Resilience4j Retry empowers your Spring Boot applications with fault tolerance capabilities. Discover the art of handling transient failures through automatic retries, configurable backoff strategies, and conditional retry logic. Build robust applications that can adapt to challenging scenarios and provide uninterrupted services.
What is Resilience?
Resilience is the ability of a system to withstand and recover from failures. In the context of software development, it refers to building applications that can handle failures gracefully and continue to provide a seamless user experience. It involves designing applications in a way that they can handle and adapt to various failure scenarios, such as network issues, service disruptions, or high-load situations. Resilient applications minimize the impact of failures and maintain stability even in challenging conditions.
Understanding the Importance of Resiliency
Considering resiliency is crucial for building robust and reliable applications. Here are a few reasons why resiliency should be a key consideration:
-
Enhanced User Experience: Resilient applications continue functioning and serving users even when failures occur, ensuring a seamless user experience.
-
Business Continuity: By handling failures gracefully, resilient applications ensure business continuity and minimize the impact of disruptions on critical operations.
-
Scalability and Performance: Resilient applications are designed to scale and handle varying loads, enabling them to meet user demands efficiently.
-
System Stability: Resilient systems are better equipped to recover from failures, reducing downtime and enhancing overall system stability.
What is Resilience4j?
Resilience4j is a lightweight, open-source library designed to help developers build resilient applications. It provides simple yet powerful tools and patterns to enhance application reliability and responsiveness. By integrating Resilience4j into their applications, developers can ensure that their software can gracefully recover from errors, adapt to changing conditions, and maintain a high level of performance, providing a better user experience overall. It offers multiple modules, each addressing a specific resilience pattern. The modules offered by Resilience4j include Retry, Circuit Breaker, Rate Limiter, Bulkhead, and Time Limiter. In this guide, we will focus on the Retry module, which allows for automatic retries of failed operations with customizable configurations.
Understanding Resilience4j Retry Module
The Resilience4j Retry module provides powerful functionality to handle transient failures and retry operations that may fail initially. It provides a flexible and configurable way to define retry policies for specific operations or methods.
With the Retry module, developers can customize parameters such as the maximum number of retries, backoff intervals between retries, and the type of exceptions that should trigger a retry. This allows them to fine-tune the retry behavior based on their specific use cases and requirements.
When an operation fails, the Retry module automatically retries the operation according to the configured policy. It intelligently manages the timing between retries, allowing for exponential or fixed delays, or even randomized intervals. This helps avoid overwhelming the system or the target service with repeated requests.
Key Features of Resilience4j Retry
The Key features of the Resilience4j Retry module include:
-
Simple Retry: Define the maximum number of retry attempts for an operation and the duration to wait between retries.
-
Retrying on Exceptions: Configure the Retry module to retry operations based on specific checked exceptions.
-
Conditional Retry: Apply conditional logic to determine whether a retry should be triggered based on the result of the previous attempt.
-
Backoff Strategies: Implement different backoff strategies to control the delay between retry attempts. Resilience4j Retry supports randomized interval and exponential interval backoff strategies.
-
Acting on Retry Events: Utilize RetryListeners to perform custom actions when retries succeed or fail, such as logging or sending notifications.
-
Fallback Method: Define a fallback method that gets executed when all retry attempts fail. This allows you to provide alternative logic or default values to handle failures gracefully.
Using the Spring Boot Resilience4j Retry
Now, we will understand how to use Resilience4j in Spring Boot. To use the Resilience4j Retry module in a Spring Boot application, follow these high-level steps:
Step 1: Add Resilience4j Retry Dependency
Include the Resilience4j Retry dependency in your Spring Boot project.
For Spring Boot 3, add resilience4j-spring-boot3 dependency in pom.xml of your application. The latest version of dependency can be obtained from here.
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot3</artifactId>
<version>{resilience4j-spring-boot3-version}</version>
</dependency>For Spring Boot 2, add resilience4j-spring-boot2 dependency in pom.xml of your application. The latest version of dependency can be obtained from here.
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot2</artifactId>
<version>{resilience4j-spring-boot2-version}</version>
</dependency>Also, add Spring Boot Actuator and Spring Boot AOP dependencies. Spring Boot Actuator dependency is optional but it can be useful for viewing the retry-related metrics and Spring Boot AOP dependency is mandatory or else retry will not work.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>Step 2: Configure Retry Instances
Define Retry instances with specific configurations. Each instance represents a logical grouping of retry policies for different operations.
Example Configuration:
resilience4j.retry:
instances:
backendA:
maxAttempts: 3
waitDuration: 10s
enableExponentialBackoff: true
exponentialBackoffMultiplier: 2
retryExceptions:
- org.springframework.web.client.HttpServerErrorException
- java.io.IOException
ignoreExceptions:
- io.github.robwin.exception.BusinessExceptionWe will look into these configuration options in detail at a later stage using various examples.
Step 3: Annotate Methods with @Retry Annotation
Annotate the methods that require retry logic with the @Retry annotation and specify the Retry instance name created in Step 2.
@Retry(name = "backendA")
public Movie getMovieDetails(String movieId) {
return movieApiClient.getMovieDetails(movieId);
}
Spring Boot Resilience4j Retry Examples
Now, we will see various configuration options that are available to configure retry in the Spring Boot application.
Imagine building a movie service website where customers can search for and discover movies. To ensure reliable and responsive movie searches, we’ll explore the various configuration options and practical examples related to the Resilience4j Retry module.
Simple Retry
Performing the retry operation using the minimal set of configuration options: max attempts and wait duration. In this case, a retry will be performed for all the exceptions that can occur while getting the movie details.
resilience4j.retry:
instances:
simpleRetry:
maxAttempts: 3
waitDuration: 5s
@Retry(name = "simpleRetry")
public Movie getMovieDetails(String movieId) {
return fetchMovieDetails(movieId);
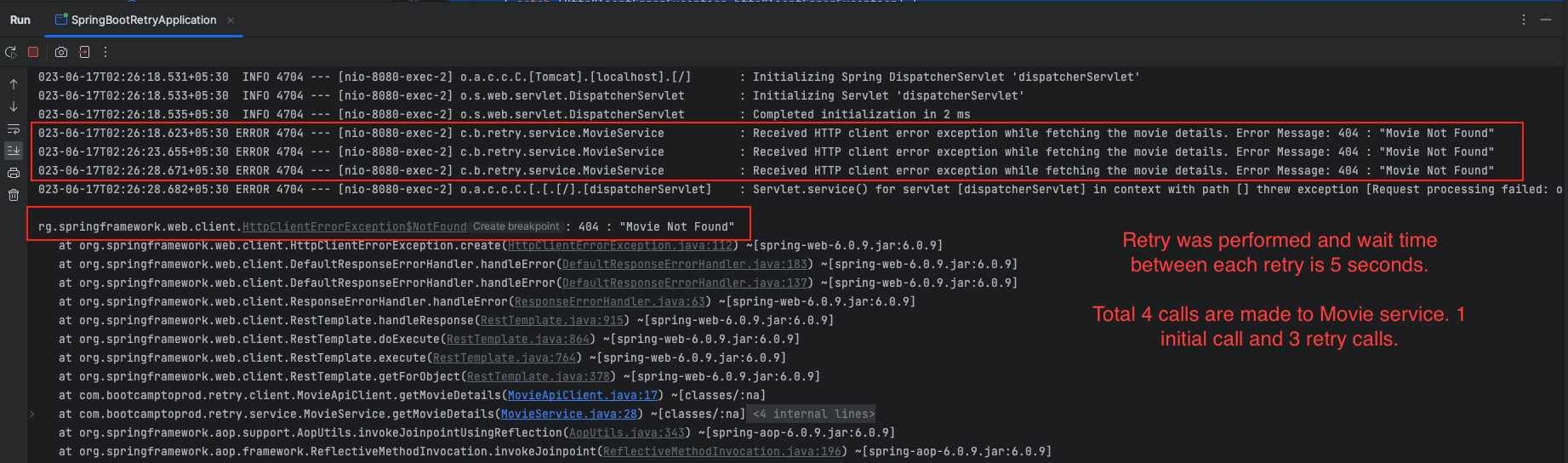
}The configuration provided for Resilience4j Retry specifies a retry configuration for a specific instance named simpleRetry. In this case, the maxAttempts is set to 3, meaning that the operation will be retried up to 3 times if it fails. The waitDuration is set to 5 seconds, indicating the amount of time to wait between each retry attempt.
Regarding exceptions, by default, Resilience4j Retry will perform retries for all exceptions that are thrown by the method, unless specific exceptions are specified in the configuration. In the given configuration snippet, no specific exceptions are mentioned, so retries will be performed for all exceptions thrown by the method.
To customize the exceptions for which retries should be performed, you can use the retryExceptions property in the configuration and provide a list of specific exception types.
Overall, with the provided configuration, the simpleRetry instance will attempt the operation up to 3 times, waiting 5 seconds between each retry, and retries will be triggered for any exception encountered.
Retrying Specific Exceptions and Ignoring Others
The retry behavior in Resilience4j can be customized by retrying specific exceptions and excluding others. We’ll leverage the following configuration as an example:
resilience4j.retry:
instances:
retryOnException:
maxAttempts: 4
waitDuration: 3s
retryExceptions:
- org.springframework.web.client.HttpClientErrorException
ignoreExceptions:
- com.bootcamptoprod.retry.exception.MovieNotFoundException
@Retry(name = "retryOnException")
public Movie getMovieDetailsRetryOnException(String movieId) {
return fetchMovieDetails(movieId);
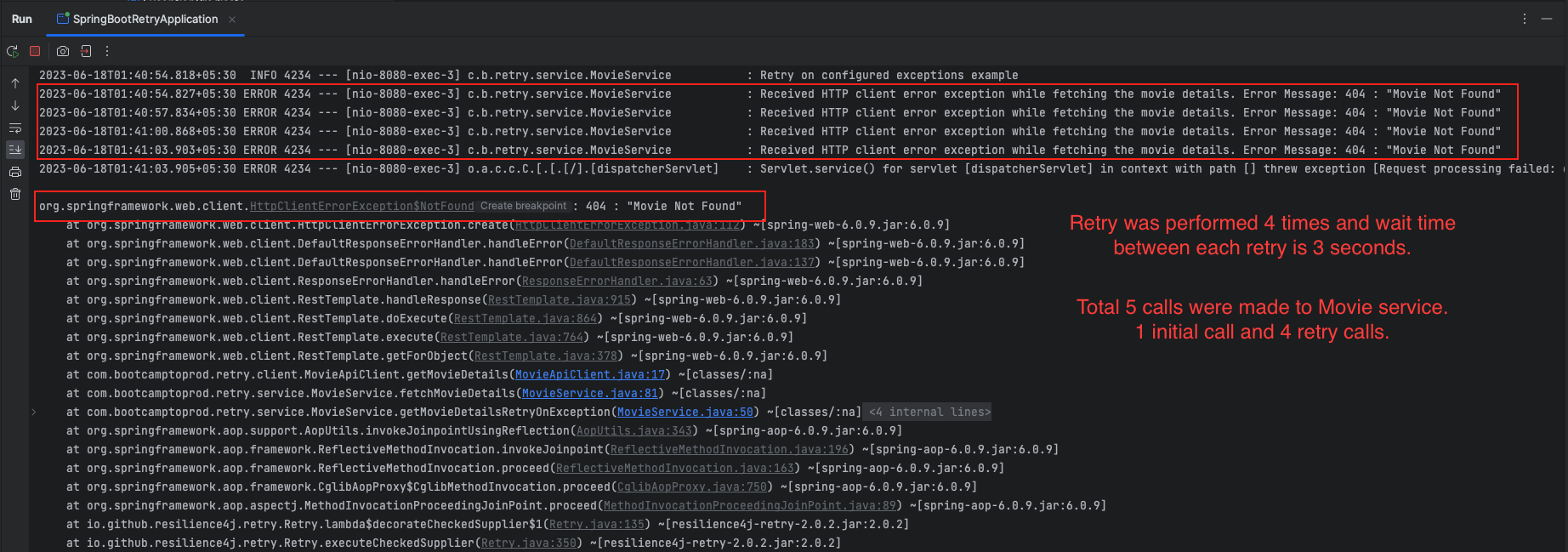
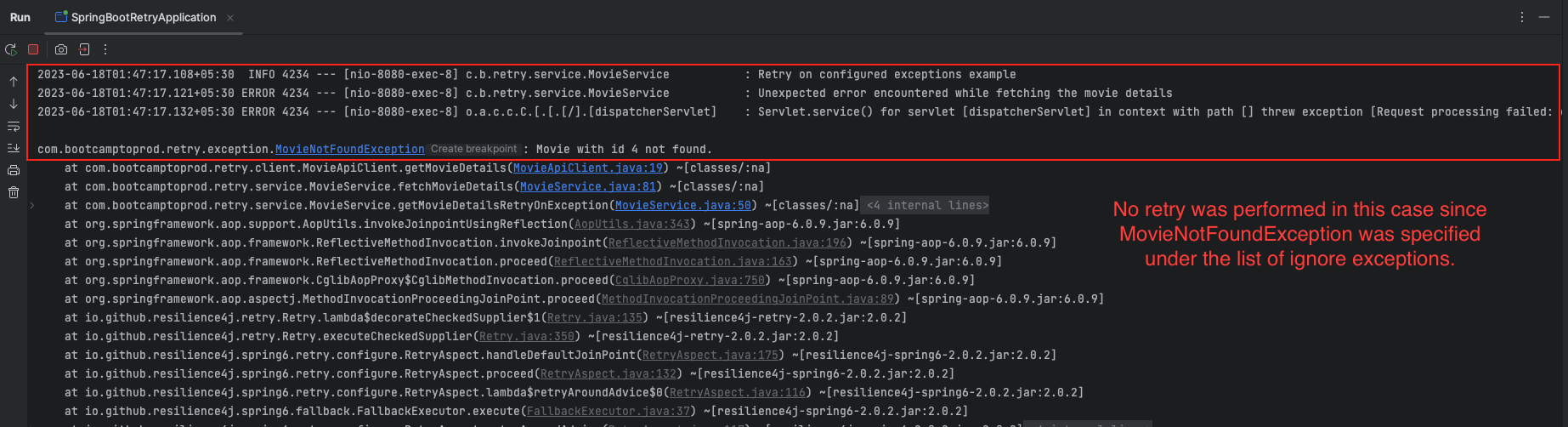
}The above Resilience4j Retry configuration sets up a retry mechanism for an operation. The configuration includes the following settings:
maxAttempts: 4: Specifies the maximum number of retry attempts, which is set to 4 in this case.waitDuration: 3s: Defines the wait duration between retry attempts, which is set to 3 seconds.
Additionally, two specific exception-related settings are included:
retryExceptions: Specifies the exceptions that should trigger a retry. In this configuration,HttpClientErrorExceptionexceptions from the Spring Web Client library will trigger a retry.ignoreExceptions: Lists the exceptions that should be ignored, meaning that they will not trigger a retry. In this case, theMovieNotFoundExceptionexception will be ignored.
Whether it is a good practice to specify both retry exceptions and ignore exceptions in the same retry instance depends on the specific use case and requirements. It can be beneficial to selectively retry certain exceptions while ignoring others to fine-tune the retry behavior based on different scenarios.
However, it’s important to carefully consider the exceptions that are being retried and those that are ignored. It is recommended to have a clear understanding of the application’s error handling and retry requirements to avoid unintended consequences and ensure that the retry mechanism aligns with the desired behavior.
Conditional Retry
You can define your own conditions using Predicates on the basis of which the retry should be performed.
Retry on Result Predicate
A result predicate in Resilience4j Retry lets you define custom rules to decide if a retry should be attempted based on the result of the operation. Let’s consider the following configuration as an example:
resilience4j.retry:
instances:
retryBasedOnConditionalPredicate:
maxAttempts: 2
waitDuration: 5s
resultPredicate: com.bootcamptoprod.retry.predicate.ConditionPredicateThe above Resilience4j Retry configuration sets up a retry mechanism based on a conditional predicate. The configuration includes the following settings:
maxAttempts: 2: Specifies the maximum number of retry attempts, which is set to 2 in this case.waitDuration: 5s: Defines the wait duration between retry attempts, which is set to 5 seconds.
In addition, a custom result predicate is defined:
resultPredicate: com.bootcamptoprod.retry.predicate.ConditionPredicate: Specifies the implementation of the result predicate, which is theConditionPredicateclass located atcom.bootcamptoprod.retry.predicate. This class implements thePredicate<Movie>interface, allowing it to evaluate a condition based on theMovieobject.
public class ConditionPredicate implements Predicate<Movie> {
@Override
public boolean test(Movie movie) {
System.out.println("Condition predicate is called.");
return movie.getId().equals("Default");
}
}The ConditionPredicate class overrides the test() method from the Predicate interface. Within this method, you can define the logic to evaluate the Response object and determine if a retry should be performed. In this example, the test() method checks if the id of the movie is equal to “Default”. If it matches, it returns true, indicating that a retry should be performed. Additionally, a message is printed to the console for each invocation of the condition predicate.
@Retry(name = "retryBasedOnConditionalPredicate")
public Movie getMovieDetailsRetryOnConditionalPredicate(String movieId) {
try {
return fetchMovieDetails(movieId);
} catch (MovieNotFoundException movieNotFoundException) {
log.info("Movie not found exception encountered. Returning default value");
return new Movie("Default", "N/A", "N/A", 0.0);
}
}By using a custom result predicate, you can define specific conditions or criteria based on the object being processed to determine if a retry is necessary. This allows you to have more control over the retry behavior based on the specific requirements of your application.

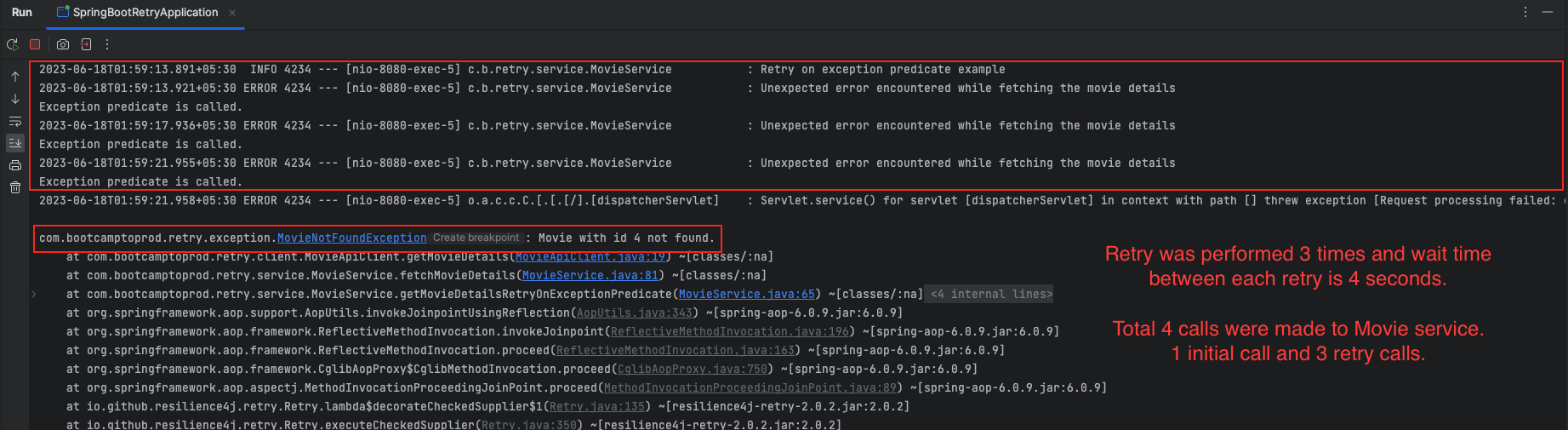
Retry on Exception Predicate
An exception predicate in Resilience4j Retry allows custom evaluation of the thrown exception to decide if a retry should be performed. Let’s understand this with the help of the following example:
resilience4j.retry:
instances:
retryBasedOnExceptionPredicate:
maxAttempts: 3
waitDuration: 4s
retryExceptionPredicate: com.bootcamptoprod.retry.predicate.ExceptionPredicateThe above Resilience4j Retry configuration sets up a retry mechanism based on an exception predicate. The configuration includes the following settings:
maxAttempts: 3: Specifies the maximum number of retry attempts, which is set to 3 in this case.waitDuration: 4s: Defines the wait duration between retry attempts, which is set to 4 seconds.
In addition, a custom exception predicate is defined:
retryExceptionPredicate: com.bootcamptoprod.retry.predicate.ExceptionPredicate: Specifies the implementation of the exception predicate, which is theExceptionPredicateclass located atcom.bootcamptoprod.retry.predicate. This class implements thePredicate<Throwable>interface, allowing it to evaluate if a retry should be performed based on the thrownThrowable.
public class ExceptionPredicate implements Predicate<Throwable> {
@Override
public boolean test(Throwable throwable) {
System.out.println("Exception predicate is called.");
return throwable instanceof MovieNotFoundException;
}
}The ExceptionPredicate class overrides the test() method from the Predicate interface. Within this method, you can define the logic to evaluate the Throwable object and determine if a retry should be performed. In this example, the test() method checks if the thrown Throwable is an instance of MovieNotFoundException. If it is, it returns true, indicating that a retry should be performed. Additionally, a message is printed to the console for each invocation of the exception predicate.
@Retry(name = "retryBasedOnExceptionPredicate")
public Movie getMovieDetailsRetryOnExceptionPredicate(String movieId) {
return fetchMovieDetails(movieId);
}By using a custom exception predicate, you can define specific conditions based on the type of exception thrown to determine if a retry should be attempted. This allows you to have more control over the retry behavior based on the specific exception types and requirements of your application.
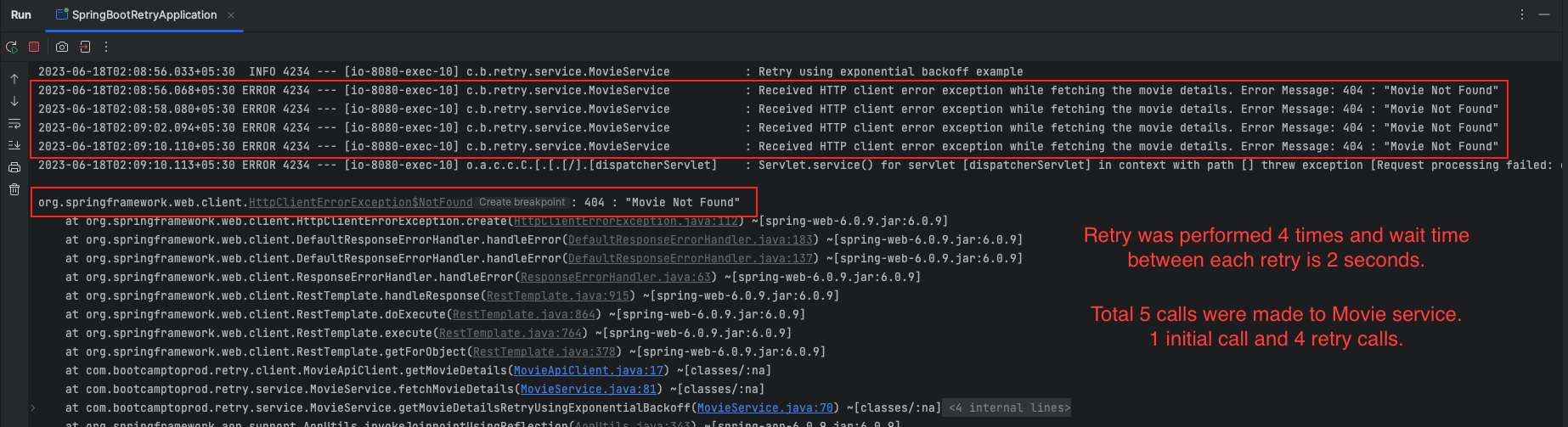
Retry with an Exponential Backoff Strategy
The exponential backoff strategy progressively increases the wait duration between retry attempts, providing a controlled and resilient approach to handling failures.
resilience4j.retry:
instances:
retryUsingExponentialBackoff:
maxAttempts: 4
waitDuration: 2s
enableExponentialBackoff: true
exponentialBackoffMultiplier: 2@Retry(name = "retryUsingExponentialBackoff")
public Movie getMovieDetailsRetryUsingExponentialBackoff(String movieId) {
return fetchMovieDetails(movieId);
}The above Resilience4j Retry configuration sets up a retry mechanism using exponential backoff. The configuration includes the following settings:
maxAttempts: 4: Specifies the maximum number of retry attempts, which is set to 4 in this case.waitDuration: 2s: Defines the initial wait duration between retry attempts, which is set to 2 seconds.enableExponentialBackoff: true: Enables the exponential backoff strategy, which increases the wait duration exponentially with each retry attempt.exponentialBackoffMultiplier: 2: Specifies the multiplier used to calculate the increased wait duration for each subsequent retry attempt.
With this configuration, the retry attempts will follow an exponential backoff pattern. After each failed attempt, the wait duration will be multiplied by the exponential backoff multiplier, which is set to 2. This means that the wait duration will progressively increase with each retry attempt.
The exponential backoff strategy is commonly used to prevent overwhelming the system and to give it some time to recover from temporary failures. By gradually increasing the wait duration, the retry mechanism becomes more resilient and reduces the likelihood of triggering additional failures.
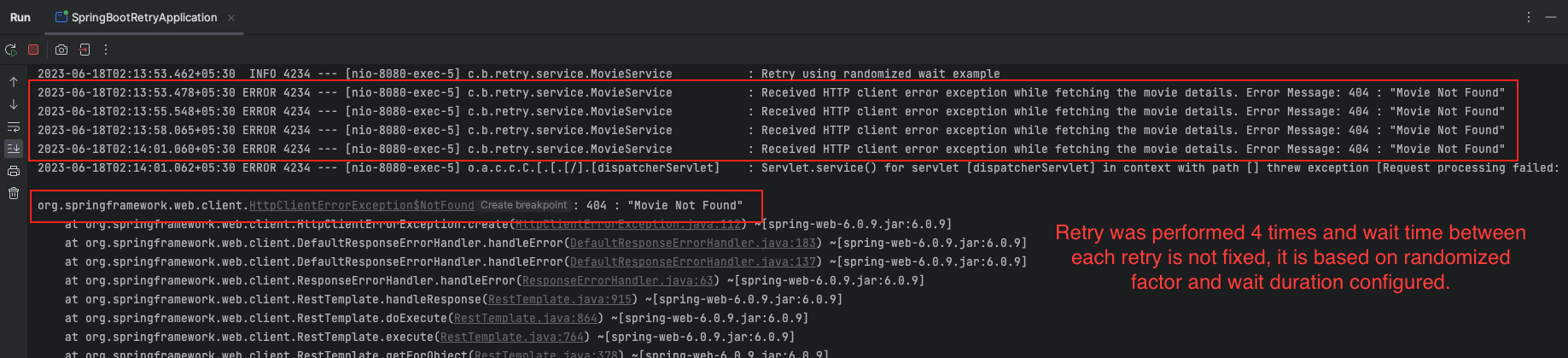
Retry with Randomized Wait
Resilience4j Retry configuration wait randomized wait adds randomness to the wait time between retries, making the retries occur at different intervals and enhancing the resilience of the system.
resilience4j.retry:
instances:
retryUsingRandomizedWait:
maxAttempts: 4
waitDuration: 2s
enableRandomizedWait: true
randomizedWaitFactor: 0.7@Retry(name = "retryUsingRandomizedWait")
public Movie getMovieDetailsRetryUsingRandomizedWait(String movieId) {
return fetchMovieDetails(movieId);
}The above Resilience4j Retry configuration sets up a retry mechanism using a randomized wait factor. The configuration includes the following settings:
maxAttempts: 4: Specifies the maximum number of retry attempts, which is set to 4 in this case.waitDuration: 2s: Defines the initial wait duration between retry attempts, which is set to 2 seconds.enableRandomizedWait: true: Enables the randomized wait factor, which introduces randomness into the wait duration.randomizedWaitFactor: 0.7: TherandomizedWaitFactordetermines the range within which the random value will be spread in relation to the specifiedwaitDuration.
The randomized wait factor introduces variability in the wait duration between retry attempts. In this case, with a randomizedWaitFactor of 0.7, the wait times generated will be between 600 milliseconds (2000 – 2000 * 0.7) and 3400 milliseconds (2000 + 2000 * 0.7). The actual wait time for each retry attempt will be randomly determined within this range.
Creating and Reusing Default Retry Configurations
You can simplify retry configuration by creating a default template that can be easily reused across multiple retry instances for consistent and efficient resilience.
Example:
resilience4j.retry:
configs:
default:
maxAttempts: 3
waitDuration: 100
retryExceptions:
- org.springframework.web.client.HttpServerErrorException
ignoreExceptions:
- com.bootcamptoprod.retry.exception.MovieNotFoundException
instances:
backendA:
baseConfig: default
backendB:
baseConfig: default
waitDuration: 2sThe configuration above demonstrates how to create a default configuration and reuse it when creating retry instances. The “resilience4j.retry” section defines a “configs” block where we define the default configuration with a unique name (“default” in this case). The default configuration includes properties such as the maximum number of attempts, wait duration, retry exceptions, and ignored exceptions.
In the “instances” block, we define different retry instances (“backendA” and “backendB”) and associate them with the “default” configuration using the “baseConfig” attribute. This allows us to reuse the same configuration for multiple retry instances, avoiding duplication of configuration code.
With this approach, we can easily create and manage multiple retry instances with consistent configurations by leveraging the default configuration.
You can even override specific configuration settings on top of the default configuration by specifying the required retry property and the value for that particular instance. This allows you to customize the retry behavior for individual instances while still leveraging the shared default configuration for common settings.
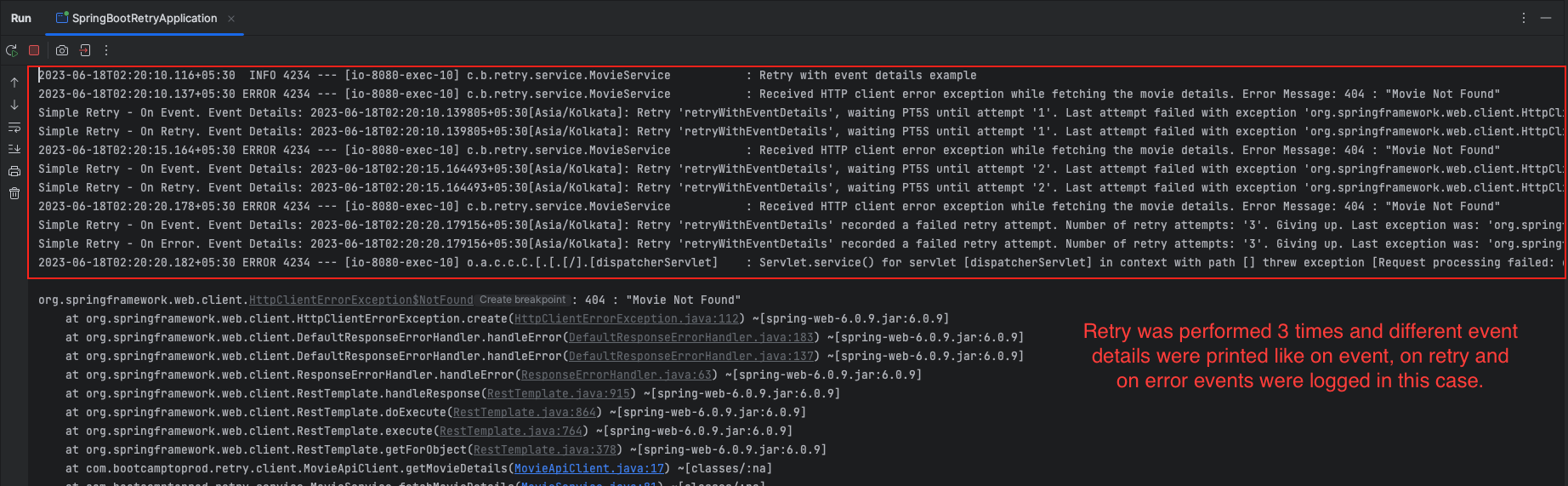
Event Listeners for Resilience4j Retry
Now, we will understand how to register event listeners for the Resilience4j Retry module in a Spring application. The event listeners capture different events that occur during the retry process and perform specific actions, such as logging or handling the events accordingly.
Example:
@Autowired
private RetryRegistry retryRegistry;
....
@Retry(name = "simpleRetry")
public Movie getMovieDetails(String movieId) {
return fetchMovieDetails(movieId);
}
....
@PostConstruct
public void postConstruct() {
io.github.resilience4j.retry.Retry.EventPublisher eventPublisher = retryRegistry.retry("simpleRetry").getEventPublisher();
eventPublisher.onEvent(event - > System.out.println("Simple Retry - On Event. Event Details: " + event));
eventPublisher.onError(event - > System.out.println("Simple Retry - On Error. Event Details: " + event));
eventPublisher.onRetry(event - > System.out.println("Simple Retry - On Retry. Event Details: " + event));
eventPublisher.onSuccess(event - > System.out.println("Simple Retry - On Success. Event Details: " + event));
eventPublisher.onIgnoredError(event - > System.out.println("Simple Retry - On Ignored Error. Event Details: " + event));
}Within postConstruct method, the eventPublisher is obtained from the retryRegistry for the “simpleRetry” Retry instance.
Next, event listeners are registered using the onEvent(), onError(), onRetry(), onSuccess(), and onIgnoredError() methods of the eventPublisher. Each event listener takes a lambda expression that defines the action to be performed when the corresponding event occurs.
onEvent()is triggered when any event occurs during the retry process.onError()is invoked when an error event occurs, indicating that the retry attempt has failed.onRetry()is called when a retry attempt is made.onSuccess()is executed when the retry operation succeeds.onIgnoredError()is fired when an error event is ignored according to the Retry configuration.
For each event, a message is printed to the console, including the event details obtained from the event parameter.
By registering these event listeners, you can customize the behavior of your Retry operations and gain visibility into the Retry process by capturing and handling different events.
Resilience4j Retry Fallback Method
In Resilience4j Retry, fallback methods play a crucial role in handling failures when all retry attempts fail. These fallback methods should be placed within the same class and have the same method signature as the retrying method, with an additional target exception parameter. This allows you to define a specific action to be taken when the retries are unsuccessful.
@Retry(name = "simpleRetry", fallbackMethod = "getMovieDetailsFallbackMethod")
public Movie getMovieDetailsWithFallback(String movieId) {
return fetchMovieDetails(movieId);
}
private Movie getMovieDetailsFallbackMethod(String movieId, MovieNotFoundException movieNotFoundException) {
log.info("Fallback method called.");
log.info("Original exception message: {}", movieNotFoundException.getMessage());
return new Movie("Default", "N/A", "N/A", 0.0);
}In the given code example, a fallback mechanism is implemented. The getMovieDetailsWithFallback method attempts to fetch movie details based on the provided movieId. If an exception, specifically a MovieNotFoundException, occurs during the retrieval process, the fallback method getMovieDetailsFallbackMethod is invoked. If any other exception is encountered apart from MovieNotFoundException, in that case, fallback method will not be called.
The getMovieDetailsFallbackMethod takes the original movieId and the caught MovieNotFoundException as parameters. It serves as a fallback option and performs alternative logic, such as logging the fallback event and creating a default movie object with placeholder values. This ensures that even if the initial movie details retrieval fails, the fallback method provides a suitable response.
It’s important to note that if there are multiple fallback methods, the one with the closest match to the thrown exception will be invoked. For example, if you want to recover from a NumberFormatException, the method with the signature containing the NumberFormatException will be called. This enables you to handle different types of exceptions in a customized manner.
Additionally, if you have multiple methods with the same return type and want to define a common fallback method for them, you can create a global fallback method with an exception parameter. This eliminates the need to define the same fallback logic multiple times, making your code more concise and maintainable.

Programmatically Creating Retry Instances
You. can create Retry instances programmatically in Resilience4j by using a custom configuration. This allows you to define specific retry settings, such as maximum attempts, wait duration, retry exceptions, and ignored exceptions.
Example:
@Configuration
public class RetryConfiguration {
@Autowired
private RetryRegistry retryRegistry;
@Bean
public Retry retryWithCustomConfig() {
RetryConfig customConfig = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofSeconds(2))
.retryExceptions(HttpClientErrorException.class, HttpServerErrorException.class)
.ignoreExceptions(MovieNotFoundException.class)
.build();
return retryRegistry.retry("customRetryConfig", customConfig);
}
} @Retry(name = "customRetryConfig")
public Movie getMovieDetailsWithCustomRetryConfig(String movieId) {
return fetchMovieDetails(movieId);
}From a high level, the code is creating a Retry instance named customRetryConfig with a custom configuration in Resilience4j. The Retry instance is created using the retryRegistry.retry() method, which takes the name of the Retry instance and the custom configuration as parameters.
The custom configuration is defined using the RetryConfig.custom() builder, specifying attributes such as the maximum number of retry attempts, the wait duration between retries, and the exceptions to retry or ignore. This allows you to customize the retry behavior based on your specific requirements.
Once the Retry instance is created, it can be used to apply retry logic to methods within your application. In the provided example, the getMovieDetailsWithCustomRetryConfig() method is annotated with @Retry and specified with the name of the custom Retry instance. This means that when the getMovieDetailsWithCustomRetryConfig() method is called, the Retry logic defined by the custom configuration will be applied.


Actuator Monitoring and Management Endpoints
The Resilience4j Retry module provides several Actuator endpoints that offer insights into the behavior and metrics of your retry configurations. These endpoints are useful for monitoring and managing the retry functionality in your application. Here’s an easy-to-understand explanation of each endpoint:
-
/actuator/retries: This endpoint provides information about all the defined retry configurations in your application. It gives you an overview of the retry instances, their names, and associated configuration details.
-
/actuator/metrics/resilience4j.retry.calls: This endpoint provides metrics related to the retry functionality. It gives you insights into the number of calls made, successful calls, failed calls, and other relevant metrics. Monitoring these metrics helps you gauge the effectiveness of your retry configurations.
-
/actuator/retryevents: This endpoint gives you access to the retry events that have occurred during the execution of your application. Retry events include information about retries, such as successful retries, failed retries, and ignored errors. It helps you track the retry behavior and understand how often retries are happening.
-
/actuator/retryevents/{name}: This endpoint provides detailed information about retry events for a specific retry instance. By specifying the name of the retry instance in the URL, you can retrieve specific retry event details, including the number of retries, the exceptions encountered, and other relevant information.
-
/actuator/retryevents/{name}/{eventType}: This endpoint allows you to filter retry events based on a specific event type for a particular retry instance. You can specify the name of the retry instance and the desired event type in the URL to retrieve specific event details, such as successful retries, failed retries, or ignored errors.
These Actuator endpoints give you visibility into the retry behavior, metrics, and event details, enabling you to monitor and analyze the resilience of your application’s retry functionality. They assist in troubleshooting, optimizing retry configurations, and ensuring the reliability of your application’s remote operations.
 Spring Boot Resilience4j Retry Actuator Retries Output
Spring Boot Resilience4j Retry Actuator Retries Output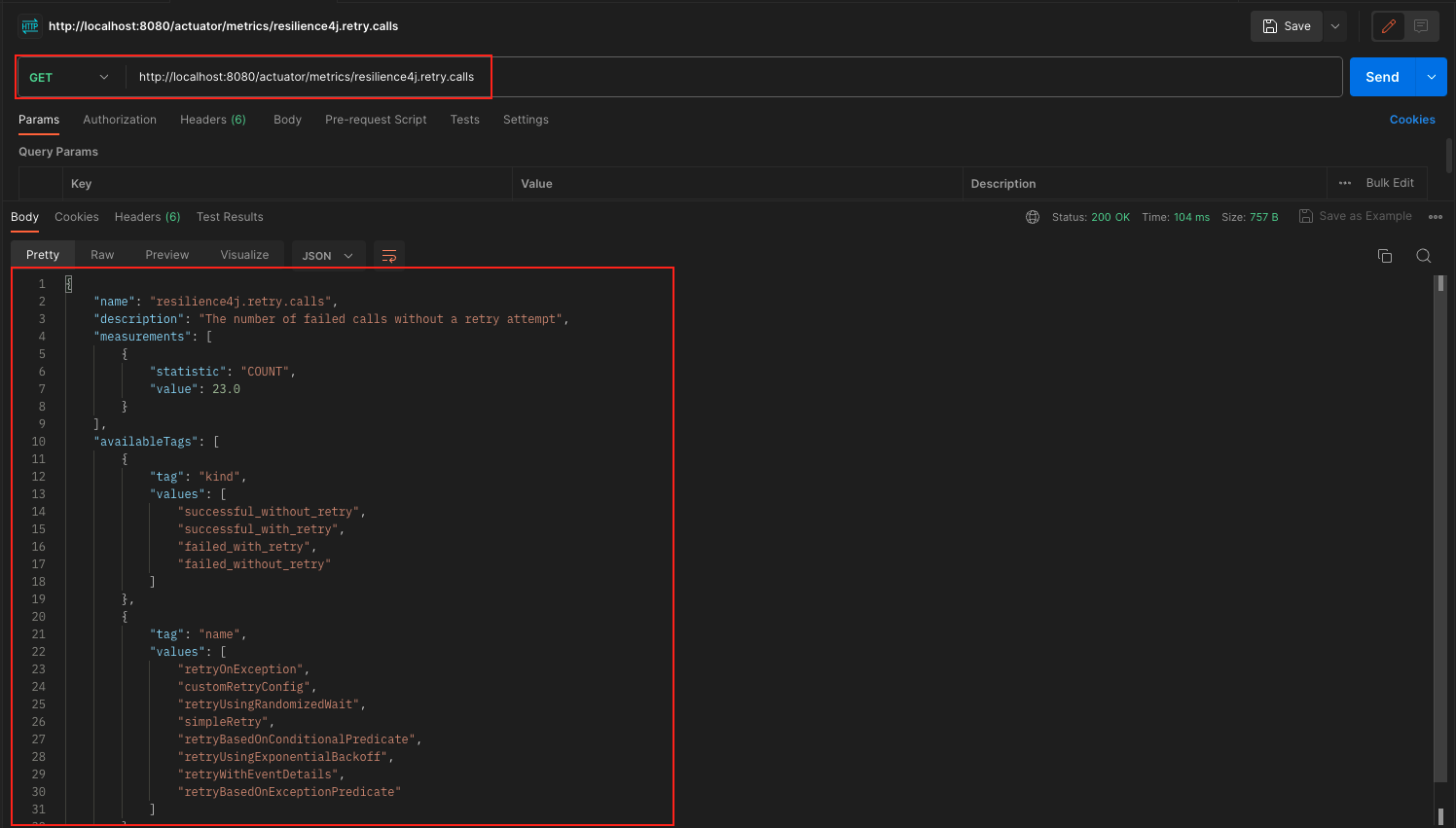 Spring Boot Resilience4j Retry Actuator Retry Calls Metrics Output
Spring Boot Resilience4j Retry Actuator Retry Calls Metrics Output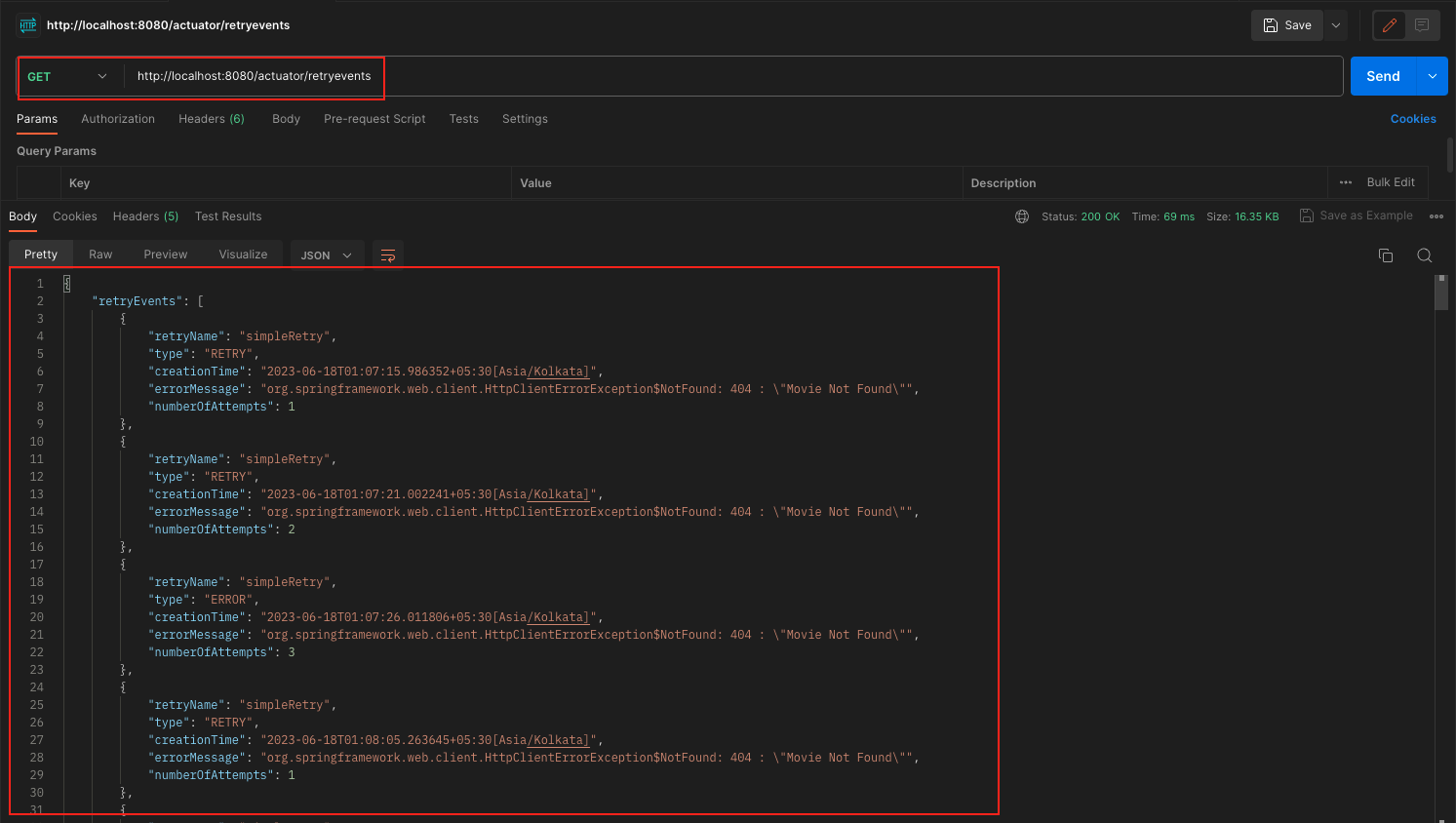 Spring Boot Resilience4j Retry Actuator Retry Events Output
Spring Boot Resilience4j Retry Actuator Retry Events Output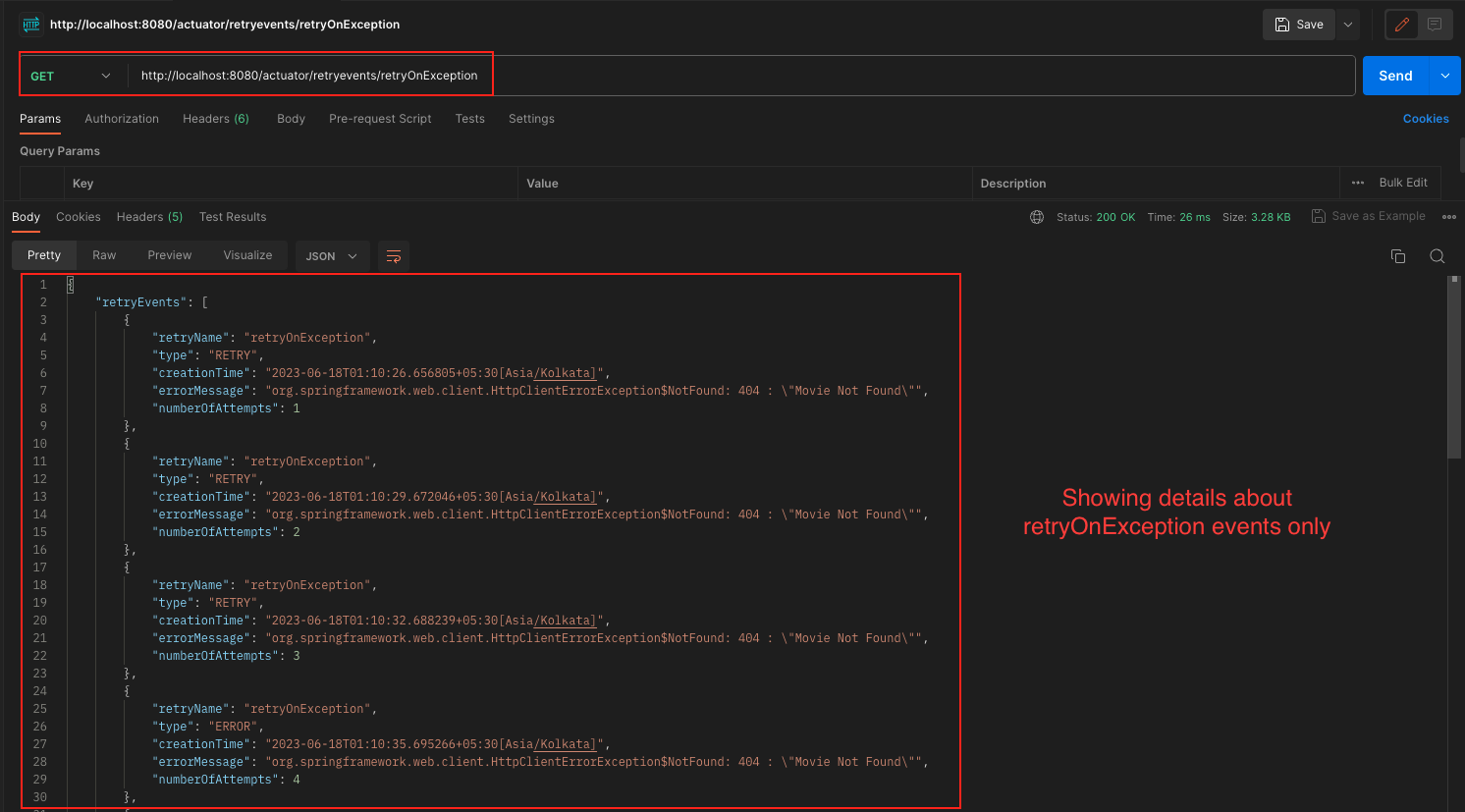 Spring Boot Resilience4j Retry Actuator Single Event Details
Spring Boot Resilience4j Retry Actuator Single Event Details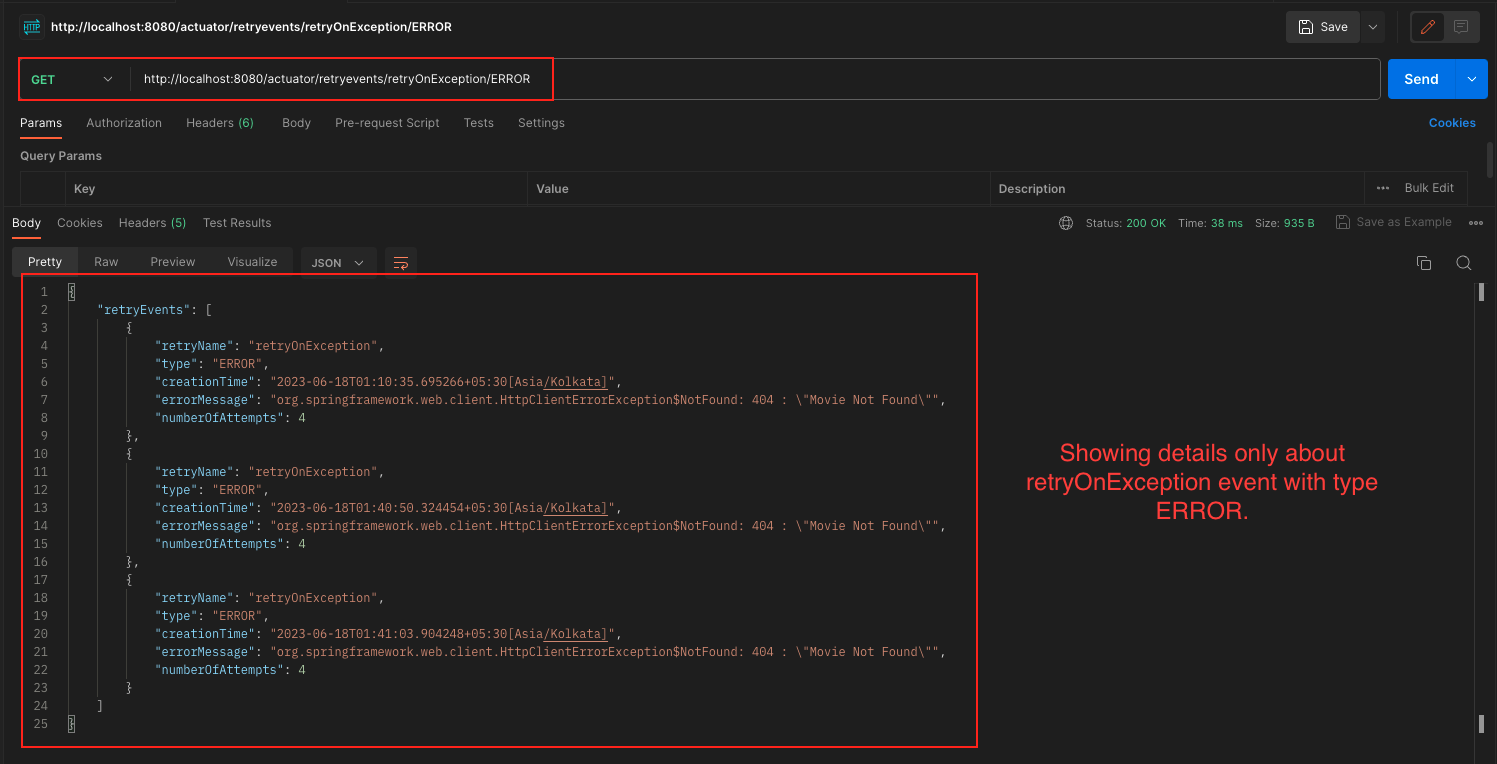 Spring Boot Resilience4j Retry Actuator Single Event Details ERROR Type
Spring Boot Resilience4j Retry Actuator Single Event Details ERROR TypeSource Code
The complete source code of the above examples and retry configurations can be found here.
Spring Retry vs Resilience4j Retry
Resilience4j Retry and Spring Boot Retry are both libraries that help developers handle retries when operations fail. However, there are some differences between the two.
Resilience4j Retry provides extensive flexibility in configuring retry policies. Developers have full control over parameters such as the maximum number of retries, backoff intervals (including exponential, fixed, and random), and the specific exceptions that should trigger a retry. This allows for fine-grained customization and adaptability to various use cases.
In contrast, Spring Boot Retry takes a more declarative approach, allowing developers to simply annotate the method they want to retry. Spring Boot Retry provides default configurations for retries but also allows customization by specifying the maximum number of retries and backoff intervals (including exponential, fixed, and random). While it doesn’t offer as much flexibility as Resilience4j Retry, it simplifies the retry setup, particularly within the Spring Boot framework.
Furthermore, Resilience4j Retry integrates seamlessly with other resilience patterns such as circuit breakers, rate limiters, and timeouts. This provides a comprehensive approach to handling failures in distributed systems. In comparison, Spring Boot Retry does not have built-in support for these additional resilience patterns.
Overall, Resilience4j Retry is a highly flexible and feature-rich library suitable for complex scenarios, while Spring Boot Retry offers a simpler and more streamlined approach specifically designed for Spring Boot applications.
You can also explore the capabilities of Spring Retry and its usefulness in handling retries within your Spring Boot applications. Learn more about it in our blog Spring Boot Retry: How to Handle Errors and Retries in Your Application!”
FAQs
Is it possible to apply different retry configurations to different methods within the same application?
Yes, with Resilience4j Retry, you can apply different retry configurations to different methods by utilizing annotations or programmatically configuring RetryRegistry beans.
Can we monitor the retries and their outcomes?
Resilience4j Retry provides Actuator endpoints that expose retry-related metrics and events. By accessing these endpoints, you can monitor the number of retries, failures, and other relevant information for your retry operations.
Can I specify specific exceptions to retry or ignore?
Yes, you can configure Resilience4j Retry to retry specific exceptions using the retryExceptions property. Similarly, you can specify exceptions to be ignored during retry using the ignoreExceptions property.
How can I handle fallback behavior in case all retry attempts fail?
Resilience4j Retry provides the option to define a fallback method using the fallbackMethod property in the @Retry annotation. This allows you to specify an alternative action or return a default value when all retry attempts fail.
Is it possible to create custom retry configurations programmatically?
Yes, Resilience4j Retry allows you to create custom retry configurations programmatically using the RetryConfig builder. This gives you fine-grained control over the retry behavior and allows you to tailor it to your specific needs.
Can I customize the backoff strategy for retry intervals in Resilience4j Retry?
Yes, Resilience4j Retry offers various backoff strategies to control the delay between retry attempts. You can choose from fixed delay, exponential backoff, and randomized backoff. Each strategy has configurable options to fine-tune the retry intervals based on your application’s needs.
Things to Consider
Here are some important considerations to keep in mind when using Resilience4j Retry:
- Identify the appropriate retry strategy: Understand the nature of the failures you’re dealing with and choose the most suitable retry strategy. Consider factors like the type of exceptions, the desired delay between retries, and the maximum number of retry attempts.
- Fine-tune retry configuration: Adjust the retry configuration parameters to align with your application’s requirements. This includes setting the maximum number of attempts, specifying the wait duration between retries, configuring the backoff strategy, and defining the retryable and ignored exceptions.
- Define fallback mechanisms: Implement fallback logic to handle situations where all retry attempts fail. A fallback method can provide a default response or an alternative action to prevent cascading failures and improve user experience.
- Monitor and analyze retry behavior: Utilize the built-in metrics and monitoring capabilities provided by Resilience4j and integrate with your preferred monitoring system. Monitor key metrics such as retry count, success rate, and failure rate to gain insights into the resilience of your application and identify areas for improvement.
- Test retry scenarios: Create comprehensive test cases to verify the behavior of your retry configuration. Simulate different failure scenarios, set expectations for retry attempts, and validate that the retry logic works as intended.
- Balance between resilience and performance: While retries can enhance application resilience, excessive retries may impact performance or cause unnecessary load on external services. Strike a balance between resilience and performance by carefully configuring the retry parameters and setting reasonable limits.
- Document and communicate retry behavior: Clearly document the retry behavior and its configuration in your code and accompanying documentation. Communicate any retry-related expectations or limitations to other developers, stakeholders, and consumers of your application.
Conclusion
Resilience4j Retry provides a robust and flexible solution for building resilient applications that can gracefully handle transient failures. By leveraging various configuration options, examples, and best practices outlined in this blog post, you can enhance the fault tolerance of your Spring Boot applications and deliver a more reliable experience to your users. Embrace the power of Resilience4j Retry and unlock the potential for building highly resilient systems.
Remember, building resilience is a continuous process, and it’s crucial to adapt and evolve your retry configurations as your application and failure scenarios change. With Resilience4j Retry, you can confidently navigate through transient failures and deliver a more resilient application.
Learn More
Interested in learning more?
Check out our blog on empowering your application with cross-domain capabilities using Spring Boot CORS
Add a Comment