
Learn how to build a Confluence MCP Server using Embabel Framework using the Confluence REST API. Step-by-step guide to create AI agents that interact with Confluence for listing spaces, creating documents, and more.
1. Introduction
Welcome back to the fifth part of our deep dive into the Embabel Framework! If you have been following along, you know we are on a journey to master building AI agents in Java using Spring Boot.
We have come a long way from the basics. Here is a quick recap of our journey so far:
- Basics & Shell Agent: We covered the fundamentals and built a meeting summarizer.
- REST API Agents: We learned how to expose our agents over HTTP.
- Decision Making: We explored how to use the Condition annotation to make smart choices.
- First MCP Server: We stepped into the future of AI by building a File Operations MCP server.
- Read here: Embabel Framework: How to Build MCP Server
Today, we’re taking another exciting step forward by building our second MCP server – this time, one that interacts with Confluence REST APIs. This tutorial will show you how MCP servers can work behind the scenes with external REST APIs to fulfill requests from AI assistants like Claude. We’ll create a Confluence MCP server that can list spaces, retrieve documents, create new pages, fetch page history, and extract document metadata – all through natural language interactions!
2. What is a Confluence MCP Server?
Before we dive into the code, let’s understand what we’re building. A Confluence MCP Server is a specialized server that acts as a bridge between AI assistants (like Claude) and your Confluence workspace.
Think of it this way: Confluence has a powerful REST API that lets you programmatically interact with spaces, pages, and documents. However, AI assistants can’t directly call these APIs. That’s where MCP (Model Context Protocol) comes in.
The MCP server exposes Confluence operations as “tools” that AI assistants can understand and use. When you ask Claude to “list all spaces in Confluence,” Claude communicates with our MCP server, which then calls the appropriate Confluence REST API and returns the results.
Real-World Use Case: Imagine you’re working on a project and need to quickly find information across multiple Confluence spaces. Instead of manually navigating through pages, you can simply ask your AI assistant: “Find all documents related to the Q4 roadmap.” The AI uses the MCP server to search Confluence and provides you with the relevant information instantly.
3. Prerequisites
Before we begin, make sure you have:
- Java 21 or higher installed
- Maven for dependency management
- Spring Boot knowledge (basic understanding is sufficient)
- Confluence account with API access
- Confluence API Token (we’ll show you how to get this)
- Basic understanding of REST APIs
3.1. Getting Your Confluence API Credentials
To interact with Confluence, we need two things:
- Base URL: Your Confluence instance URL (e.g.,
https://your-domain.atlassian.net) - API Token: An authentication token for secure access
Steps to get your API token:
- Log in to your Atlassian account
- Go to Account Settings → Security → API tokens
- Click “Create and manage API tokens” > “Create API token”
- Give it a name (e.g., “Embabel MCP Server”)
- Copy the generated token (you won’t see it again!)
- Create a Base64-encoded credential:
email:api_token
For example, if your email is john@example.com and your token is abc123, encode john@example.com:abc123 in Base64.
echo -n john@example.com:abc123 | base644. Build MCP Server: Confluence MCP Server
In this tutorial, we will create a Confluence MCP Server with five core capabilities that allow an AI to manage your knowledge base:
- List Spaces: Retrieve a list of all available spaces in the Confluence instance.
- List Documents in Space: Fetch all pages/documents residing within a specific space.
- Create Document: Create a new page in a specific space with a custom title and content provided.
- Get Page History: Retrieve the version history of a specific document to see how it has changed over time.
- Get Document Metadata: Fetch detailed metadata about a specific document.
Our server will expose these operations through the Model Context Protocol (MCP). This means you can connect an AI client (like the Claude Desktop App) to this server, and simply ask it: “Read the latest docs in the Engineering space and create a summary page.” The AI will figure out which API calls to make to fulfill your request!
⚙️ Project Structure & Setup
Before we dive into the code, let’s understand how our project is organized:
embabel-confluence-mcp-server
├── src
│ └── main
│ ├── java
│ │ └── com
│ │ └── bootcamptoprod
│ │ ├── config
│ │ │ └── ConfigureOpenRouterModels.java # LLM configuration (OpenRouter)
│ │ ├── dto
│ │ │ ├── ConfluenceResponse.java # Standard response wrapper
│ │ │ ├── CreateDocumentRequest.java # Input for creating pages
│ │ │ ├── DocumentIdRequest.java # Input for ID-based lookups
│ │ │ └── SpaceKeyRequest.java # Input for space-based lookups
│ │ ├── mcp
│ │ │ └── ConfluenceMcpAgent.java # Main MCP agent exposing tools
│ │ ├── service
│ │ │ └── ConfluenceService.java # Logic for Confluence REST API calls
│ │ └── EmbabelConfluenceMcpServerApplication.java # Spring Boot main class
│ └── resources
│ └── application.yml # App & Confluence configuration
└── pom.xml # Maven dependencies
Understanding the Project Structure
Here’s a quick breakdown of what each key file and package does:
- ConfluenceMcpAgent.java: This is the core of our application. It defines the Embabel Agent that exposes our Confluence capabilities (List Spaces, Create Document, etc.) to the outside world.
- service package (ConfluenceService.java): This class handles the “heavy lifting” of communicating with Atlassian Confluence Rest APIs.
- dto package (CreateDocumentRequest.java, ConfluenceResponse.java, etc.): This directory holds our Data Transfer Objects (DTOs). These are simple Java Records that define the “inputs” and “outputs” for our AI tools.
- EmbabelConfluenceMcpServerApplication.java: The main class that boots up our Spring Boot application.
- ConfigureOpenRouterModels.java: A Spring @Configuration class responsible for setting up the LLM connection. Even though this is an MCP server, Embabel requires an LLM configuration to initialize the internal agent context. We are using free models via OpenRouter for this demonstration.
- application.yml: Our configuration file. This is where we define the application name, set the default Language Model (LLM), and most importantly, configure the Confluence Base URL and Auth Tokens (using environment variable placeholders) to keep our credentials secure.
- pom.xml: The Maven project file. It manages all our project’s dependencies. The most important addition here is embabel-agent-starter-mcpserver, which automatically configures the SSE endpoints and protocol handlers required to make our application a functioning MCP server.
Diving Into the Code
Let’s break down each component of our application.
Step 1: Setting Up Maven Dependencies
First, let’s set up our Maven project with all necessary dependencies. The pom.xml file defines our project configuration and required libraries:
<properties>
<java.version>21</java.version>
<embabel-agent.version>0.3.0</embabel-agent.version>
</properties>
<dependencies>
<!-- Spring Boot Web for REST endpoints -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot Actuator for health checks -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Embabel MCP Server Starter - The magic ingredient! -->
<dependency>
<groupId>com.embabel.agent</groupId>
<artifactId>embabel-agent-starter-mcpserver</artifactId>
<version>${embabel-agent.version}</version>
</dependency>
<!-- OpenAI Compatible Model Support -->
<dependency>
<groupId>com.embabel.agent</groupId>
<artifactId>embabel-agent-starter-openai</artifactId>
<version>${embabel-agent.version}</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.embabel.agent</groupId>
<artifactId>embabel-agent-dependencies</artifactId>
<version>${embabel-agent.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>embabel-releases</id>
<url>https://repo.embabel.com/artifactory/libs-release</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>embabel-snapshots</id>
<url>https://repo.embabel.com/artifactory/libs-snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
What’s Important Here:
- This Maven configuration sets up our Spring Boot project with Java 21.
- The key dependency here is
embabel-agent-starter-mcpserver. This starter library does all the heavy lifting. This single dependency brings in all MCP server capabilities. It also automatically configures endpoints (specifically Server-Sent Events or SSE) that allow MCP clients to connect to your Java application. - We also included
embabel-agent-starter-openai. You might wonder why we need an LLM dependency if we are just building a server for tools. Even though our MCP server’s tools are just deterministic Java code, the Embabel framework requires at least one LLM model to be configured to initialize its internal agent context. In our case, we will use this to configure free models from OpenRouter. - We’ve also included custom repositories to fetch the latest Embabel artifacts.
- The Actuator dependency adds health checks and metrics endpoints for production monitoring.
Step 2: Configure Application Properties
Next, let’s configure our application settings in application.yml:
spring:
application:
name: embabel-mcp-file-server
embabel:
models:
defaultLlm: x-ai/grok-4.1-fast:free
confluence:
baseUrl: ${CONFLUENCE_BASE_URL}
auth:
apiToken: ${CONFLUENCE_AUTH_TOKEN}📄 Configuration Overview
- spring.application.name: Identifies our application in logs and monitoring tools
- embabel.models.defaultLlm: Specifies which AI model to use (we’re using Grok 4.1 via OpenRouter)
- confluence.baseUrl: Your Confluence REST API endpoint (set via environment variable)
- confluence.auth.apiToken: Your Base64-encoded credentials (set via environment variable)
Setting Environment Variables: For security, we don’t hardcode credentials. Instead, set these environment variables while starting your MCP server:
CONFLUENCE_BASE_URL="https://your-domain.atlassian.net/wiki/api/v2"
CONFLUENCE_AUTH_TOKEN="confluence-base64-encoded-token"
OPENAI_API_KEY="your-openrouter-api-key"Step 3: Application Entry Point
This is the main class that bootstraps our entire application.
package com.bootcamptoprod;
import com.embabel.agent.config.annotation.EnableAgents;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@EnableAgents
@SpringBootApplication
public class EmbabelConfluenceMcpServerApplication {
public static void main(String[] args) {
SpringApplication.run(EmbabelConfluenceMcpServerApplication.class, args);
}
}
Explanation:
- This is our Spring Boot application entry point. This class bootstraps both Spring Boot and Embabel frameworks simultaneously.
- It scans for
@Agentclasses, exposes them via MCP protocol, sets up SSE endpoints, and also configures tool discovery
Step 4: Create Data Transfer Object (DTOs)
Our DTOs define the structure of data flowing through the application.
package com.bootcamptoprod.dto;
public record SpaceKeyRequest(String spaceKey) {
}Purpose: This DTO is used when we need to specify which Confluence space to operate on. For example, when listing all documents in the “Software Development” space, we pass spaceKey = "123".
package com.bootcamptoprod.dto;
public record DocumentIdRequest(String documentId) {
}Purpose: Used when we need to reference a specific document by its ID, such as fetching page history or metadata for document 12345.
package com.bootcamptoprod.dto;
public record CreateDocumentRequest(String spaceKey, String title, String content) {
}Purpose: Contains all the information needed to create a new Confluence page: which space to create it in, what title to give it, and what content to include.
package com.bootcamptoprod.dto;
import java.util.Map;
public record ConfluenceResponse(Map<String, Object> response) {
}
Purpose: A generic wrapper for all responses from Confluence. Using Map<String, Object> provides flexibility to handle various response structures from the Confluence API.
Step 5: Configuring LLM Models
This configuration class sets up multiple LLM models via OpenRouter, a unified API gateway for various AI models. Here’s what’s happening:
package com.bootcamptoprod.config;
import com.embabel.agent.openai.OpenAiCompatibleModelFactory;
import com.embabel.common.ai.model.Llm;
import com.embabel.common.ai.model.PerTokenPricingModel;
import io.micrometer.observation.ObservationRegistry;
import org.jetbrains.annotations.NotNull;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.time.LocalDate;
@Configuration
public class ConfigureOpenRouterModels extends OpenAiCompatibleModelFactory {
public ConfigureOpenRouterModels(@NotNull ObservationRegistry observationRegistry,
@Value("${OPENAI_API_KEY}") String apiKey) {
super(
"https://openrouter.ai",
apiKey,
"/api/v1/chat/completions",
null,
observationRegistry
);
}
@Bean
public Llm mistral7b_free() {
return openAiCompatibleLlm(
"mistralai/mistral-7b-instruct:free",
new PerTokenPricingModel(0.0, 0.0),
"OpenRouter",
LocalDate.of(2024, 10, 1)
);
}
@Bean
public Llm deepseek_r1_t2() {
return openAiCompatibleLlm(
"tngtech/deepseek-r1t2-chimera:free",
new PerTokenPricingModel(0.0, 0.0),
"OpenRouter",
LocalDate.of(2025, 5, 28)
);
}
@Bean
public Llm glm_4_5_air() {
return openAiCompatibleLlm(
"z-ai/glm-4.5-air:free",
new PerTokenPricingModel(0.0, 0.0),
"OpenRouter",
LocalDate.of(2025, 5, 28)
);
}
@Bean
public Llm grok_4_1_free() {
return openAiCompatibleLlm(
"x-ai/grok-4.1-fast:free",
new PerTokenPricingModel(0.0, 0.0),
"OpenRouter",
LocalDate.of(2025, 11, 28)
);
}
}Explanation:
- This configuration class registers OpenRouter as an AI model provider.
- By extending
OpenAiCompatibleModelFactory, we leverage OpenRouter’s OpenAI-compatible API. - The constructor configures the base URL and endpoint for OpenRouter API.
- The
@Value("${OPENAI_API_KEY}")annotation injects your API key, which you must provide as an environment variable when running the application. - The LLM beans methods create different model instances with zero pricing (useful for free tier or internal tracking) and metadata about the model.
- The
PerTokenPricingModel(0.0, 0.0)indicates these are free-tier models with no cost per token. - The
ObservationRegistryintegration enables automatic metrics collection for model usage.
Why Multiple Models? Having multiple models configured gives you flexibility to switch between them without code changes
Step 6: Building the Confluence Service Layer
The service layer handles all interactions with the Confluence REST API. This separation of concerns keeps our code clean and testable:
package com.bootcamptoprod.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.web.client.RestTemplateBuilder;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.Map;
@Service
public class ConfluenceService {
private static final Logger logger = LoggerFactory.getLogger(ConfluenceService.class);
private final RestTemplate restTemplate;
public ConfluenceService(RestTemplateBuilder builder,
@Value("${confluence.auth.apiToken}") String apiToken,
@Value("${confluence.baseUrl}") String confluenceBaseUrl) {
this.restTemplate = builder
.rootUri(confluenceBaseUrl)
.defaultHeader("Authorization", "Basic " + apiToken)
.build();
logger.info("ConfluenceService initialized");
}
/**
* List all spaces in Confluence.
*/
public Map<String, Object> listSpaces() {
logger.info("Fetching list of spaces from Confluence...");
try {
ResponseEntity<Map> response = restTemplate.getForEntity("/spaces", Map.class);
logger.info("Successfully retrieved spaces.");
return response.getBody();
} catch (Exception e) {
logger.error("Error listing spaces: {}", e.getMessage(), e);
return Map.of("error", "Error listing spaces: " + e.getMessage());
}
}
/**
* List documents in a specific space.
*/
public Map<String, Object> listDocumentsInSpace(String spaceKey) {
logger.info("Fetching documents in space: {}", spaceKey);
try {
ResponseEntity<Map> response = restTemplate.getForEntity("/spaces/{spaceKey}/pages", Map.class, spaceKey);
logger.info("Successfully retrieved documents in space: {}", spaceKey);
return response.getBody();
} catch (Exception e) {
logger.error("Error listing documents in space {}: {}", spaceKey, e.getMessage(), e);
return Map.of("error", "Error listing documents: " + e.getMessage());
}
}
/**
* Create a new document with specified content.
*/
public Map<String, Object> createDocument(String spaceKey, String title, String content) {
logger.info("Creating a new document '{}' in space '{}'", title, spaceKey);
try {
String payload = """
{
"spaceId": "%s",
"status": "current",
"title": "%s",
"body": {
"representation": "storage",
"value": "%s"
}
}
""".formatted(spaceKey, title, content);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<String> request = new HttpEntity<>(payload, headers);
ResponseEntity<Map> response = restTemplate.postForEntity("/pages", request, Map.class);
logger.info("Successfully created document '{}' in space '{}'", title, spaceKey);
return response.getBody();
} catch (Exception e) {
logger.error("Error creating document '{}' in space '{}': {}", title, spaceKey, e.getMessage(), e);
return Map.of("error", "Error creating document: " + e.getMessage());
}
}
/**
* Extract page history of a specific document.
*/
public Map<String, Object> getPageHistory(String documentId) {
logger.info("Fetching page history for document: {}", documentId);
try {
ResponseEntity<Map> response = restTemplate.getForEntity("/pages/{id}/versions", Map.class, documentId);
logger.info("Successfully retrieved page history for document: {}", documentId);
return response.getBody();
} catch (Exception e) {
logger.error("Error fetching page history for document {}: {}", documentId, e.getMessage(), e);
return Map.of("error", "Error fetching page history: " + e.getMessage());
}
}
/**
* Extract metadata of a specific document.
*/
public Map<String, Object> getDocumentMetadata(String documentId) {
logger.info("Fetching metadata for document: {}", documentId);
try {
ResponseEntity<Map> response = restTemplate.getForEntity("/pages/{id}", Map.class, documentId);
logger.info("Successfully retrieved metadata for document: {}", documentId);
return response.getBody();
} catch (Exception e) {
logger.error("Error fetching metadata for document {}: {}", documentId, e.getMessage(), e);
return Map.of("error", "Error fetching document metadata: " + e.getMessage());
}
}
}
Notice that there is no AI code in this class. It’s just pure Java logic.
Key Features of ConfluenceService:
- RestTemplate Configuration: We configure
RestTemplatein the constructor with the base URL and authentication header, so every request is automatically authenticated. - Error Handling: Each method includes try-catch blocks to gracefully handle API failures, returning user-friendly error messages instead of crashing.
- Logging: Comprehensive logging helps with debugging and monitoring in production environments.
- Endpoint Mapping: Each method maps to a specific Confluence REST API endpoint:
/spaces→ List all spaces/spaces/{spaceKey}/pages→ List documents in a space/pages→ Create a new page/pages/{id}/versions→ Get page history/pages/{id}→ Get page metadata
Real-World Example: When the AI assistant asks to create a document titled “Q1 Goals” in the “PROJ” space, the createDocument() method constructs a JSON payload with the space ID, title, and content, then sends it to Confluence’s API endpoint.
Step 7: Building the MCP Server (The Heart of Our Tutorial!)
Now comes the exciting part – building our actual MCP server! Create ConfluenceMcpAgent.java:
package com.bootcamptoprod.mcp;
import com.bootcamptoprod.dto.ConfluenceResponse;
import com.bootcamptoprod.dto.CreateDocumentRequest;
import com.bootcamptoprod.dto.DocumentIdRequest;
import com.bootcamptoprod.dto.SpaceKeyRequest;
import com.bootcamptoprod.service.ConfluenceService;
import com.embabel.agent.api.annotation.AchievesGoal;
import com.embabel.agent.api.annotation.Action;
import com.embabel.agent.api.annotation.Agent;
import com.embabel.agent.api.annotation.Export;
import com.embabel.agent.domain.io.UserInput;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
@Agent(description = "An MCP agent exposing Confluence operations.")
public class ConfluenceMcpAgent {
private static final Logger logger = LoggerFactory.getLogger(ConfluenceMcpAgent.class);
private final ConfluenceService confluenceService;
public ConfluenceMcpAgent(ConfluenceService confluenceService) {
this.confluenceService = confluenceService;
logger.info("ConfluenceMcpAgent initialized");
}
/**
* List all spaces in Confluence.
*/
@Action
@AchievesGoal(
description = "List all spaces in Confluence.",
export = @Export(remote = true, name = "listSpaces", startingInputTypes = UserInput.class)
)
public ConfluenceResponse listSpaces() {
logger.info("Agent action: listSpaces");
ConfluenceResponse confluenceResponse = new ConfluenceResponse(confluenceService.listSpaces());
return confluenceResponse;
}
/**
* List documents in a specific space.
*/
@Action
@AchievesGoal(
description = "List documents in a Confluence space.",
export = @Export(remote = true, name = "listDocumentsInSpace", startingInputTypes = SpaceKeyRequest.class)
)
public ConfluenceResponse listDocumentsInSpace(SpaceKeyRequest spaceKeyRequest) {
logger.info("Agent action: listDocumentsInSpace for space='{}'", spaceKeyRequest.spaceKey());
return new ConfluenceResponse(confluenceService.listDocumentsInSpace(spaceKeyRequest.spaceKey()));
}
/**
* Create a new document with specified content.
*/
@Action
@AchievesGoal(
description = "Create a new Confluence page in a space.",
export = @Export(remote = true, name = "createDocument", startingInputTypes = CreateDocumentRequest.class)
)
public ConfluenceResponse createDocument(CreateDocumentRequest createDocumentRequest) {
logger.info("Agent action: createDocument in space='{}' title='{}'", createDocumentRequest.spaceKey(), createDocumentRequest.title());
return new ConfluenceResponse(confluenceService.createDocument(createDocumentRequest.spaceKey(), createDocumentRequest.title(), createDocumentRequest.content()));
}
/**
* Get version history for a page/document.
*/
@Action
@AchievesGoal(
description = "Fetch page history for a Confluence document.",
export = @Export(remote = true, name = "getPageHistory", startingInputTypes = DocumentIdRequest.class)
)
public ConfluenceResponse getPageHistory(DocumentIdRequest documentIdRequest) {
logger.info("Agent action: getPageHistory for documentId='{}'", documentIdRequest.documentId());
return new ConfluenceResponse(confluenceService.getPageHistory(documentIdRequest.documentId()));
}
/**
* Get metadata for a specific document.
*/
@Action
@AchievesGoal(
description = "Fetch metadata for a Confluence document.",
export = @Export(remote = true, name = "getDocumentMetadata", startingInputTypes = DocumentIdRequest.class)
)
public ConfluenceResponse getDocumentMetadata(DocumentIdRequest documentIdRequest) {
logger.info("Agent action: getDocumentMetadata for documentId='{}'", documentIdRequest.documentId());
return new ConfluenceResponse(confluenceService.getDocumentMetadata(documentIdRequest.documentId()));
}
}
Explanation:
This is the heart of our application – the Confluence MCP Agent. Unlike a chatbot that simply generates text, this agent exposes specific “Tools” that an external AI (like Claude or ChatGPT) can remotely control to interact with your Confluence instance.
- @Agent: This annotation marks the class as an Embabel agent. The description (“An MCP agent exposing Confluence operations…”) is crucial here because the connecting AI client reads this description to understand the high-level purpose of this server.
- @Action: This annotation denotes the specific actions (capabilities) that the agent can perform.
- @AchievesGoal: This is the most important annotation for building an MCP server. It wraps the logic with metadata.
- description: A human-readable explanation of what the tool does (e.g., “Create a new Confluence page…”). The AI uses this description to decide which tool to call based on the user’s request.
- @Export(remote = true, …): This is the magic switch. By setting remote = true, we tell Embabel to expose this method over the Model Context Protocol so external clients can see it.
- name: This sets the specific tool name (e.g., “createDocument”) that the AI will see in its tool list.
- startingInputTypes: This tells Embabel exactly what data structure this tool needs. For example, CreateDocumentRequest.class tells the AI it needs to find a Space Key, Title, and Content before calling this tool.
- listSpaces, createDocument, getPageHistory: These are the actual tool implementations. When the AI decides to “create a page,” it sends a structured request which triggers the corresponding Java method. Notice that these methods are deterministic—they delegate the work to our ConfluenceService to make actual REST API calls. This ensures that the action happens exactly as requested without hallucination.
- CreateDocumentRequest / SpaceKeyRequest: You will notice every action takes a specific DTO (Data Transfer Object) as a parameter. Embabel automatically extracts the relevant information from the user’s natural language prompt and populates these Java objects for us.
- Service Delegation: Instead of putting complex HTTP logic inside the Agent, we inject the ConfluenceService. The Agent acts as a clean interface, accepting instructions from the AI and passing them to the Service layer to execute the API calls.
5. How to Test Your MCP Server
Now let’s test our server! We’ll cover two methods: MCP Inspector and Claude Desktop.
Method 1: Using MCP Inspector (Web Based)
The MCP Inspector is a developer tool created by the Model Context Protocol team to test servers.
Step 1: Install Node.js Make sure Node.js is installed on your system (version 22.7.5 or higher recommended).
Step 2: Start Your Server
# Set your OpenRouter API key
export OPENAI_API_KEY=your_openrouter_api_key_here
# Set your Confluence Credentials
export CONFLUENCE_BASE_URL=https://your-domain.atlassian.net/wiki/api/v2
export CONFLUENCE_AUTH_TOKEN=confluence_api_token
# Run the application
mvn spring-boot:runYour server will start on http://localhost:8080.
Step 3: Launch MCP Inspector Open a new terminal and run:
npx @modelcontextprotocol/inspector
Step 4: Connect to Your Server
- A browser window will open automatically
- Configure the connection:
- Transport Type: SSE
- URL:
http://localhost:8080/sse - Connection Type: Via Proxy
- Click Connect
Step 5: Test Operations
Navigate to the Tools section and click List Tools. You should see five tools:
- listSpaces
- listDocumentsInSpace
- getPageHistory
- getDocumentMetadata
- createDocument

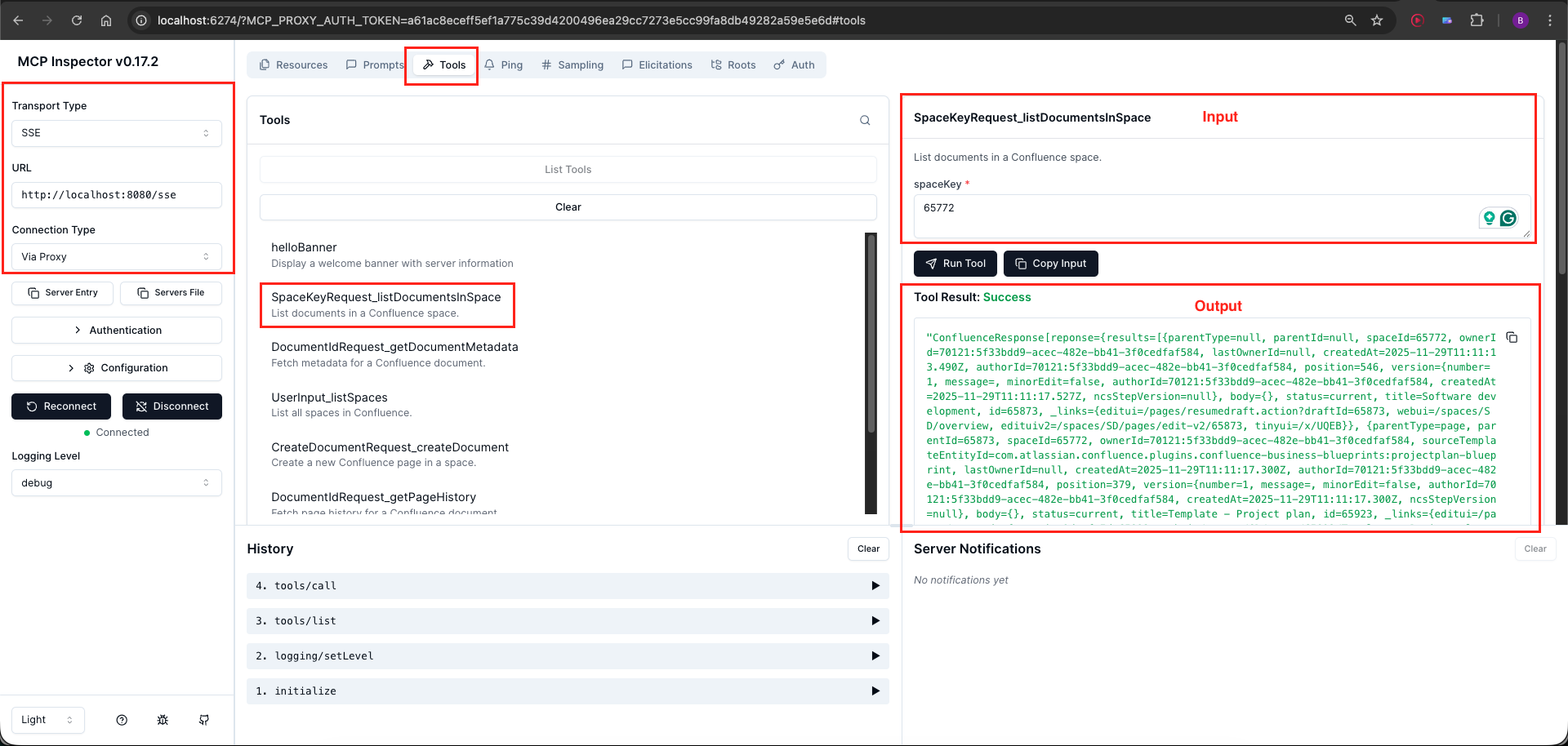
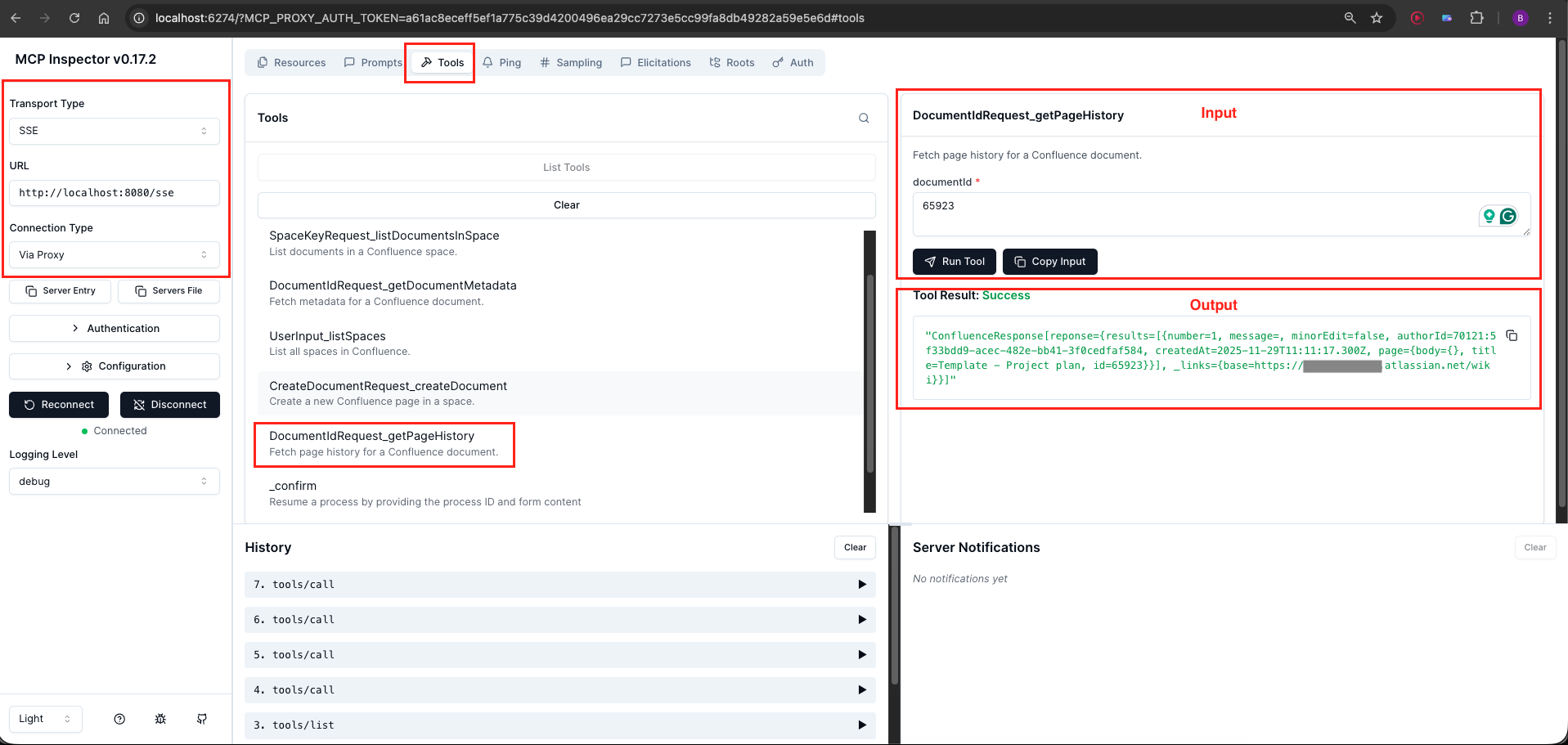
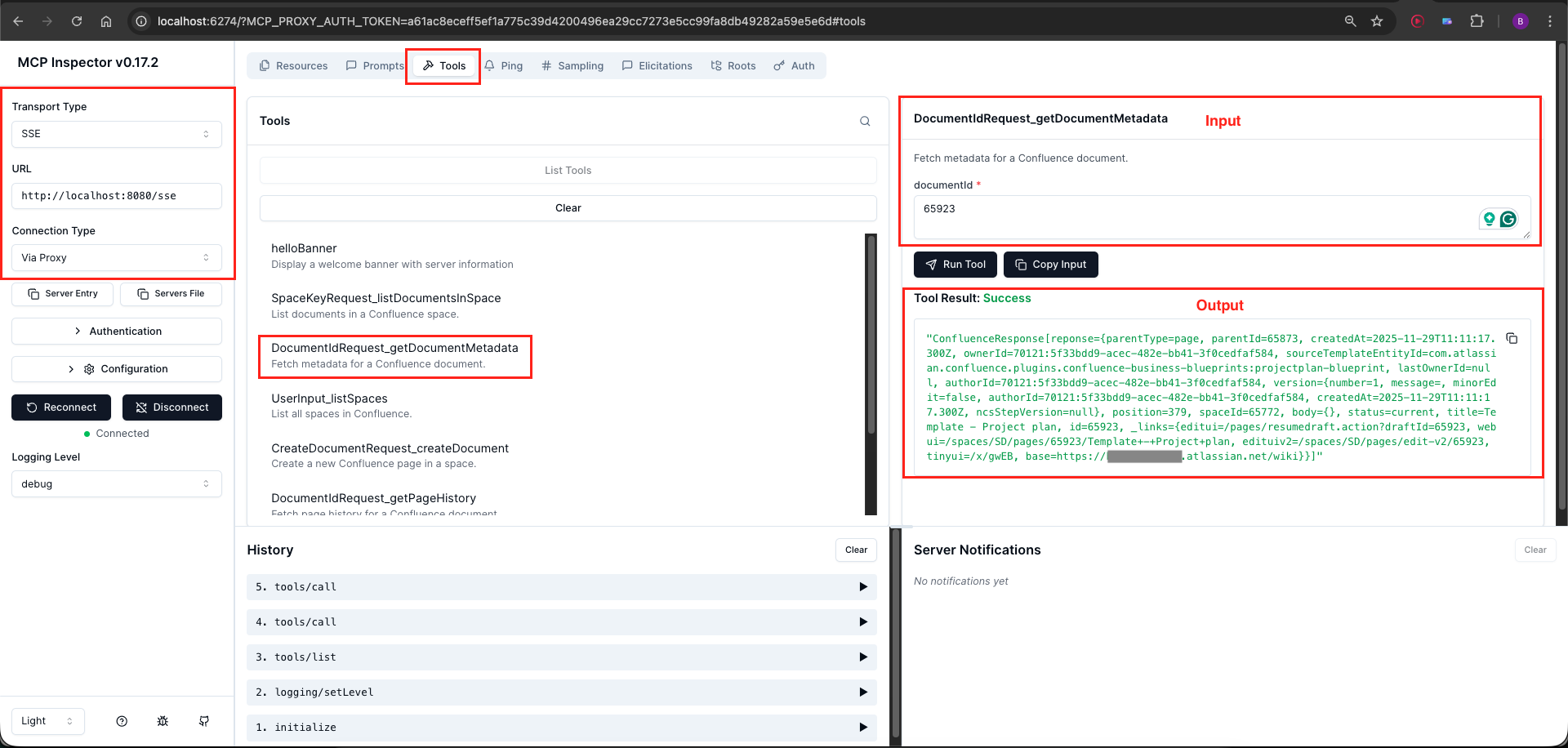
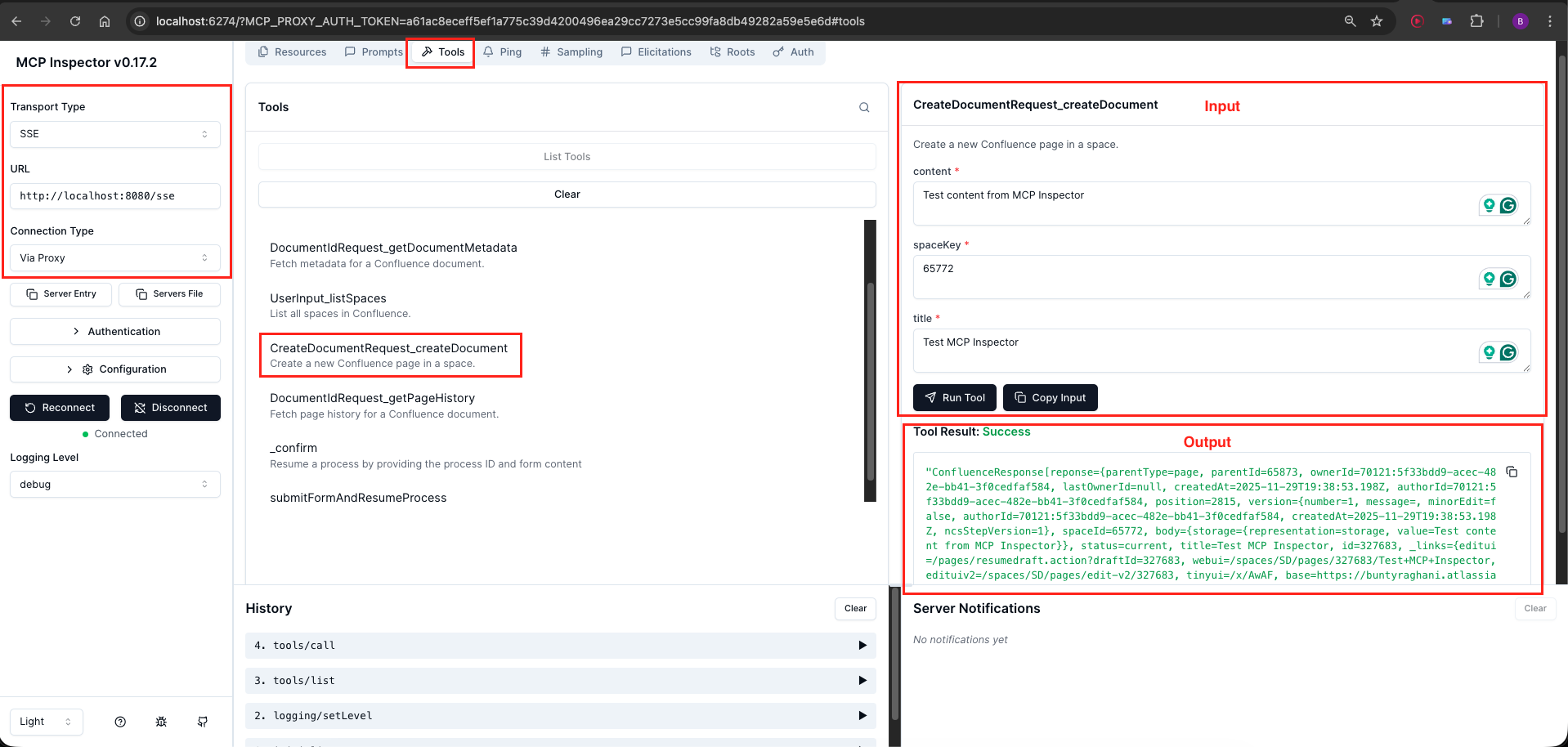

Method 2: Using Claude Desktop
Now let’s integrate our MCP server with Claude Desktop for a real AI assistant experience!
Step 1: Locate Claude Desktop Config
Find your claude_desktop_config.json file:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json
Step 2: Add MCP Server Configuration
Edit the file to add our server:
{
"mcpServers": {
"embabel-mcp-server": {
"command": "npx",
"args": [
"-y",
"mcp-remote",
"http://localhost:8080/sse"
]
}
}
}Configuration Explained:
- embabel-mcp-server: Friendly name for your server
- command: Uses npx to run the mcp-remote package
- mcp-remote: Bridge that connects Claude Desktop to SSE-based MCP servers
- URL: Points to your local server’s SSE endpoint
Step 3: Restart Claude Desktop
Close and reopen Claude Desktop completely for the configuration to take effect.
Step 4: Verify Connection
Look for “Search and tools” option in Claude Desktop’s interface. Click it to see available tools. You should see: listSpaces – listDocumentsInSpace – getPageHistory – getDocumentMetadata – createDocument
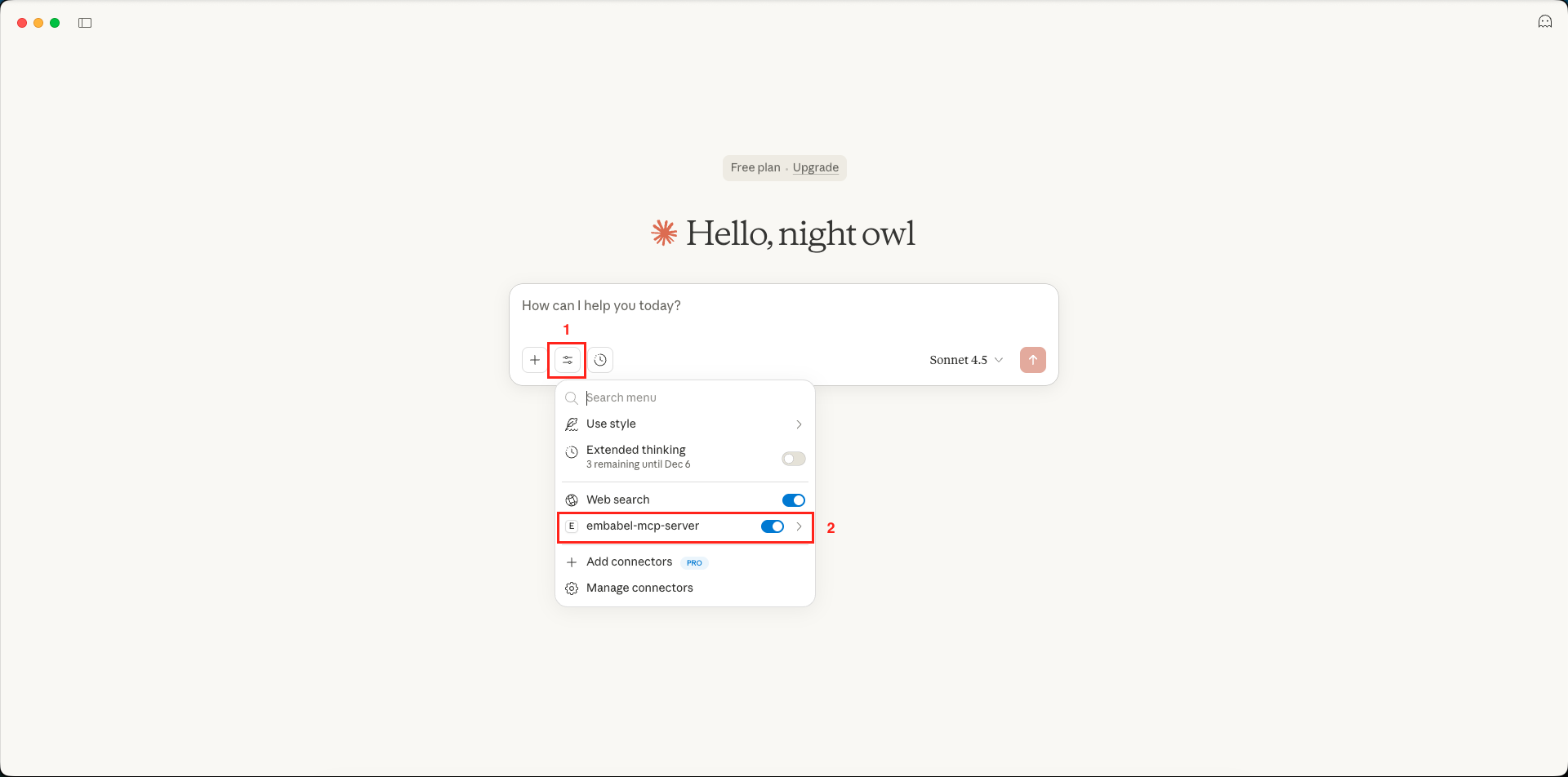
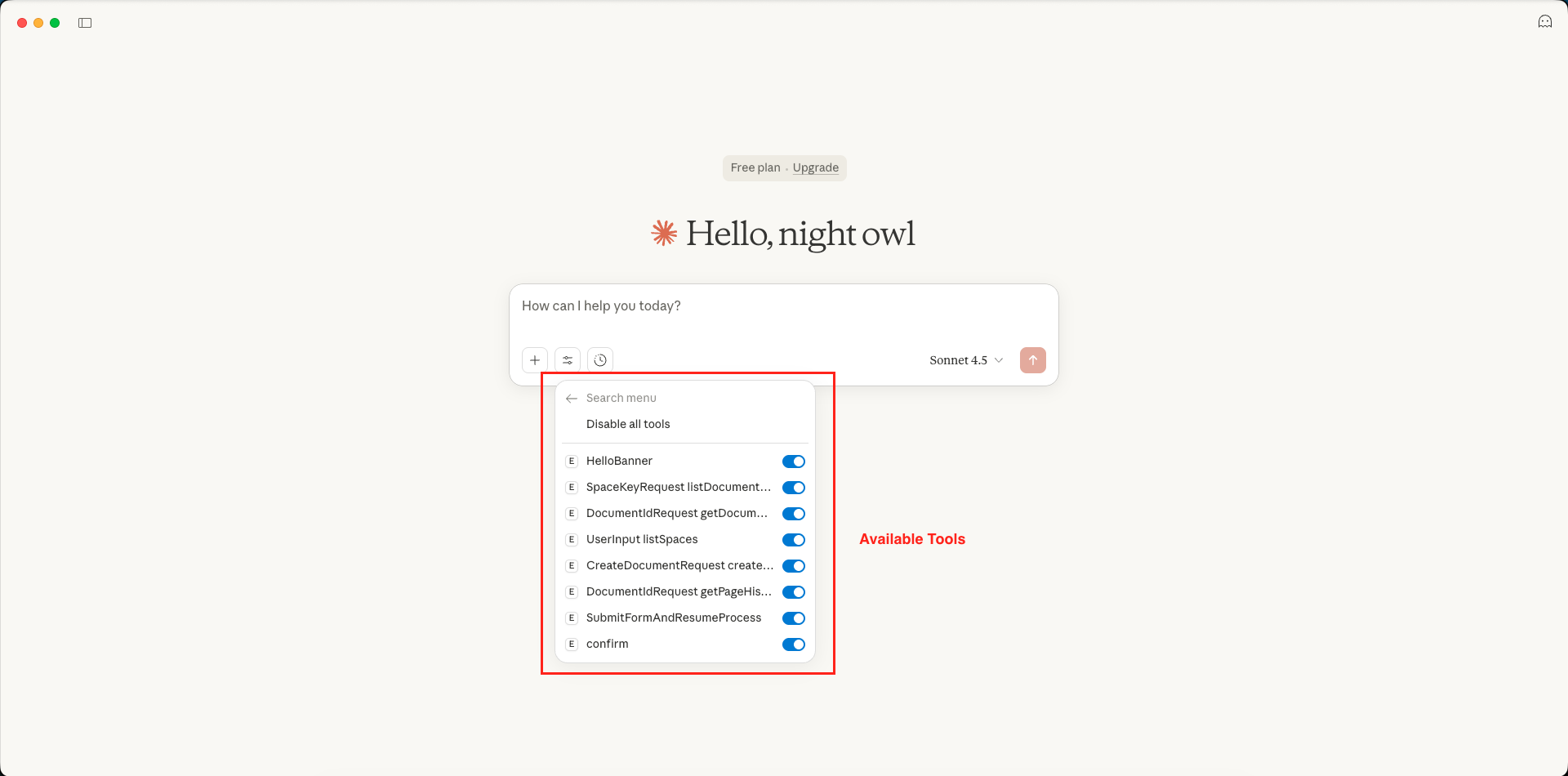
Step 5: Test with Natural Language
Now you can interact with your Confluence MCP server using natural language!
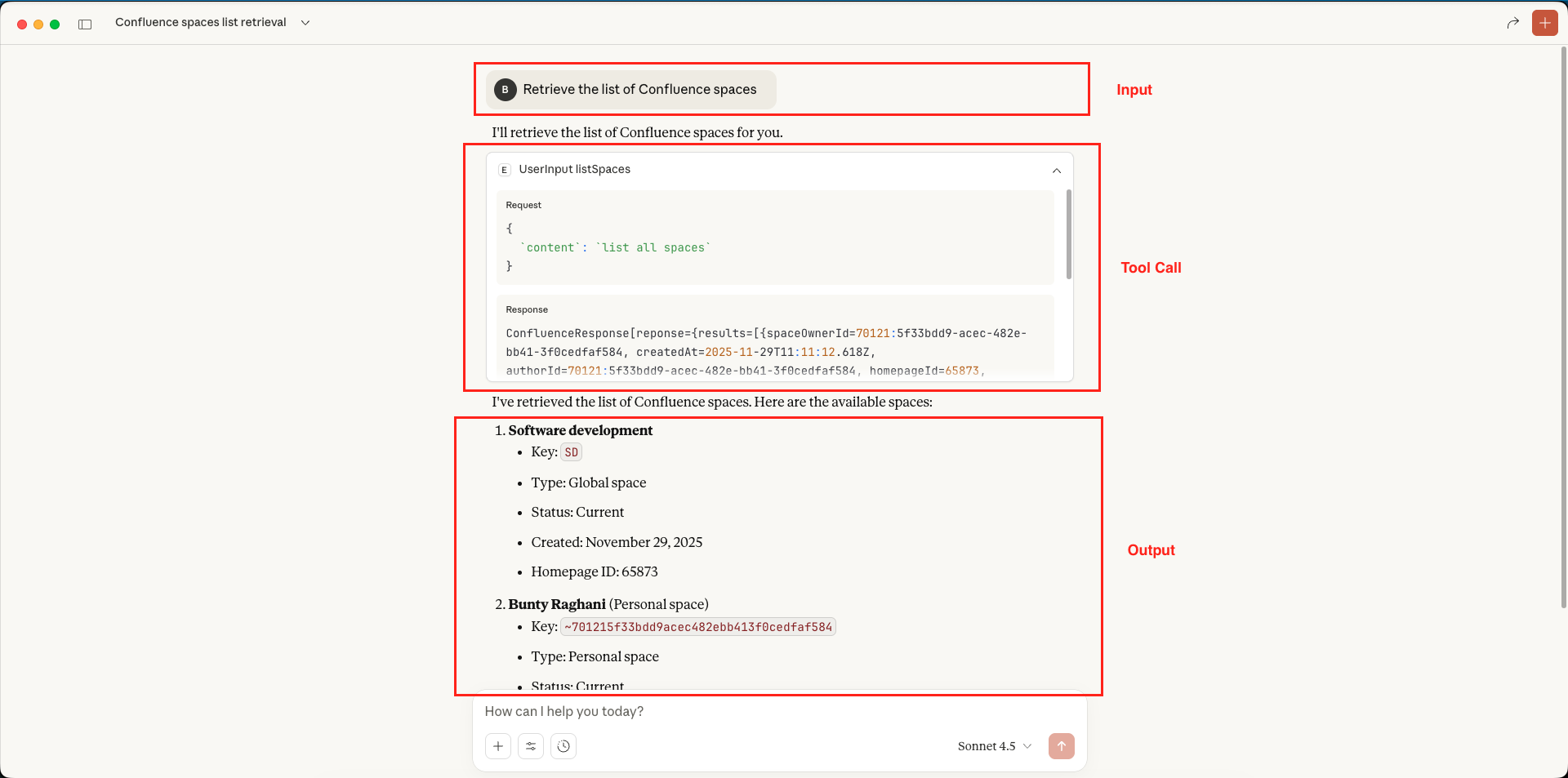 Confluence MCP Server – List All Spaces – Claude Desktop
Confluence MCP Server – List All Spaces – Claude Desktop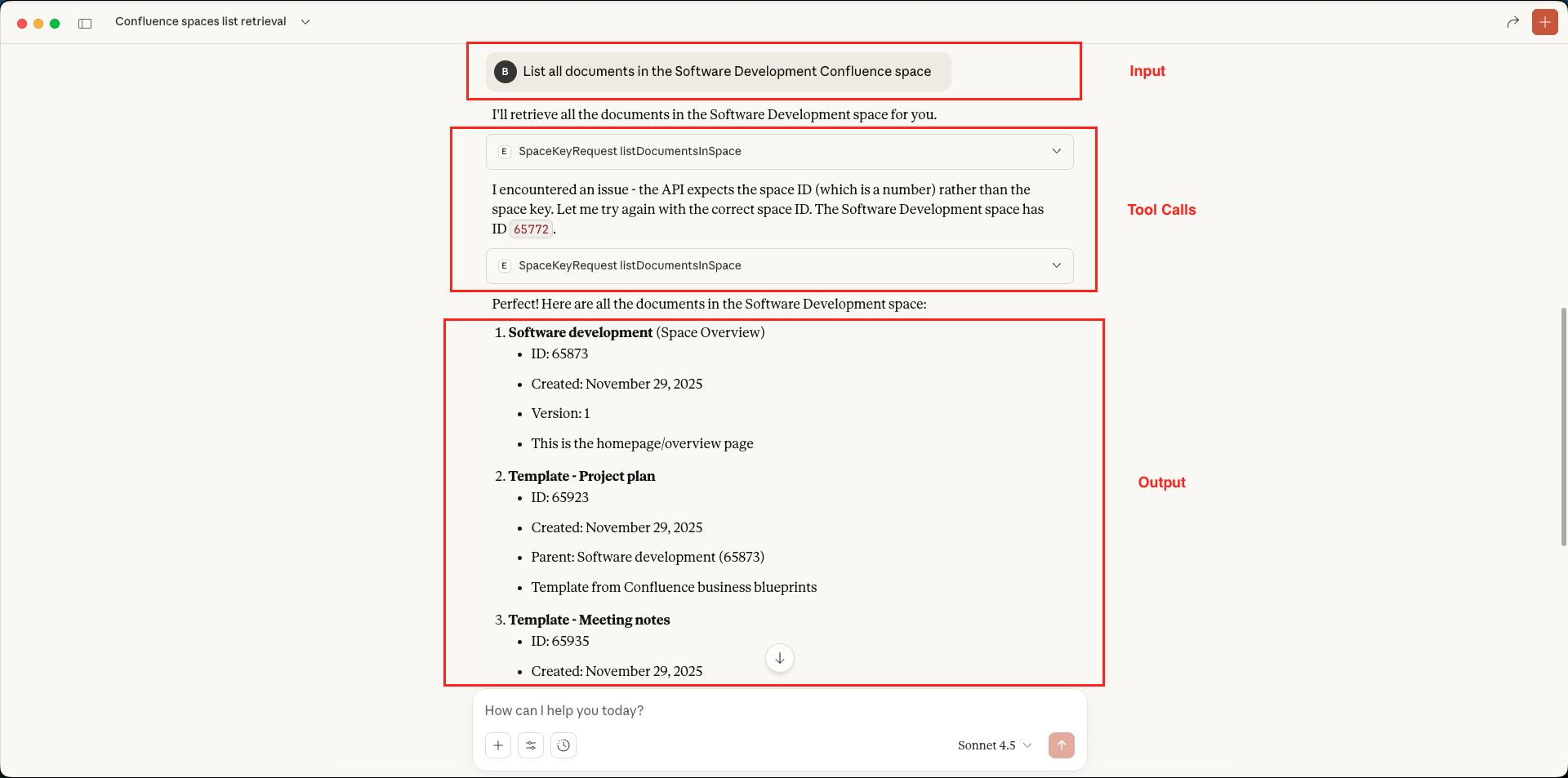 Confluence MCP Server – List Documents in Specified Space – Claude Desktop
Confluence MCP Server – List Documents in Specified Space – Claude Desktop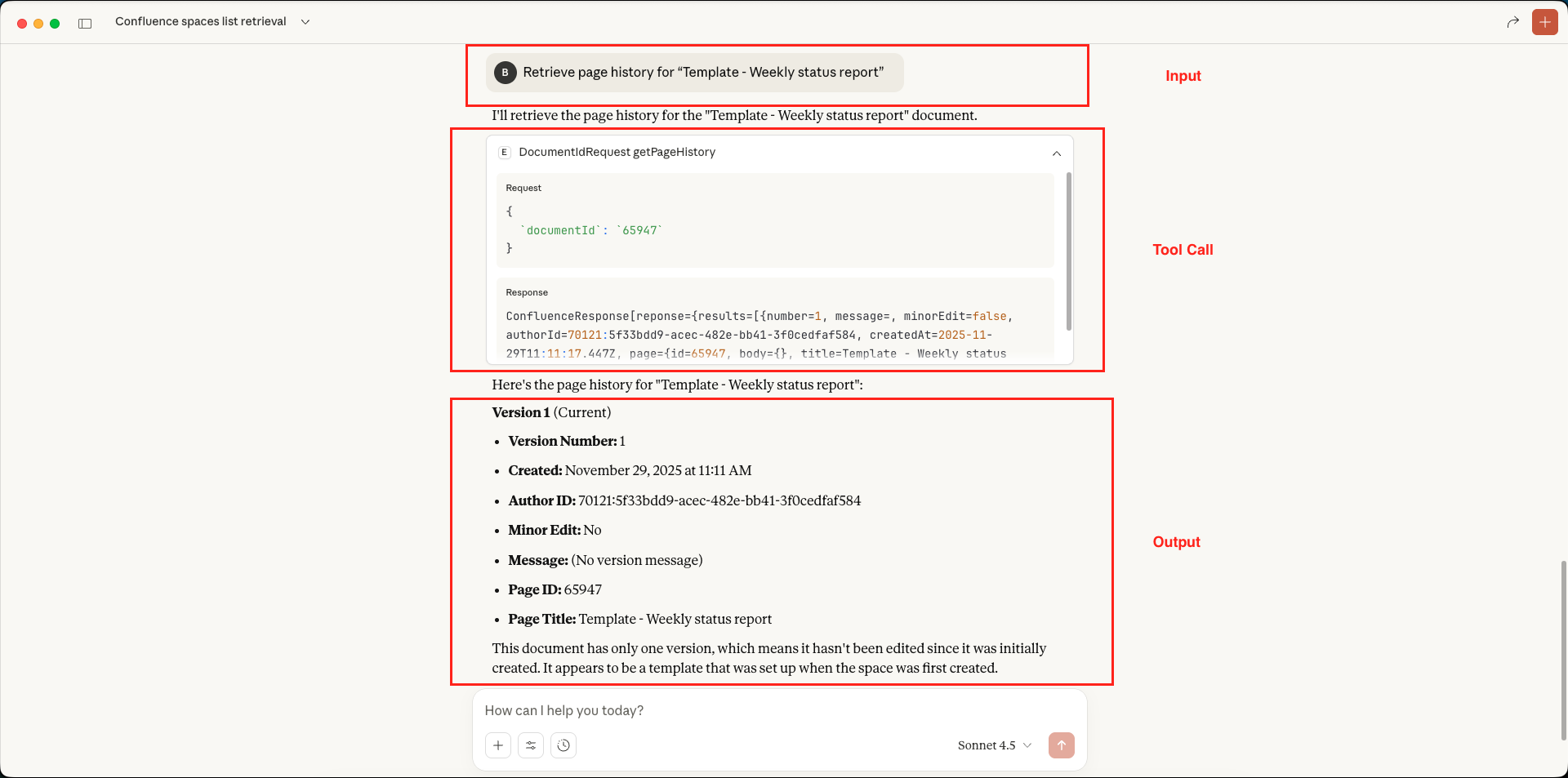 Confluence MCP Server – Get Page History – Claude Desktop
Confluence MCP Server – Get Page History – Claude Desktop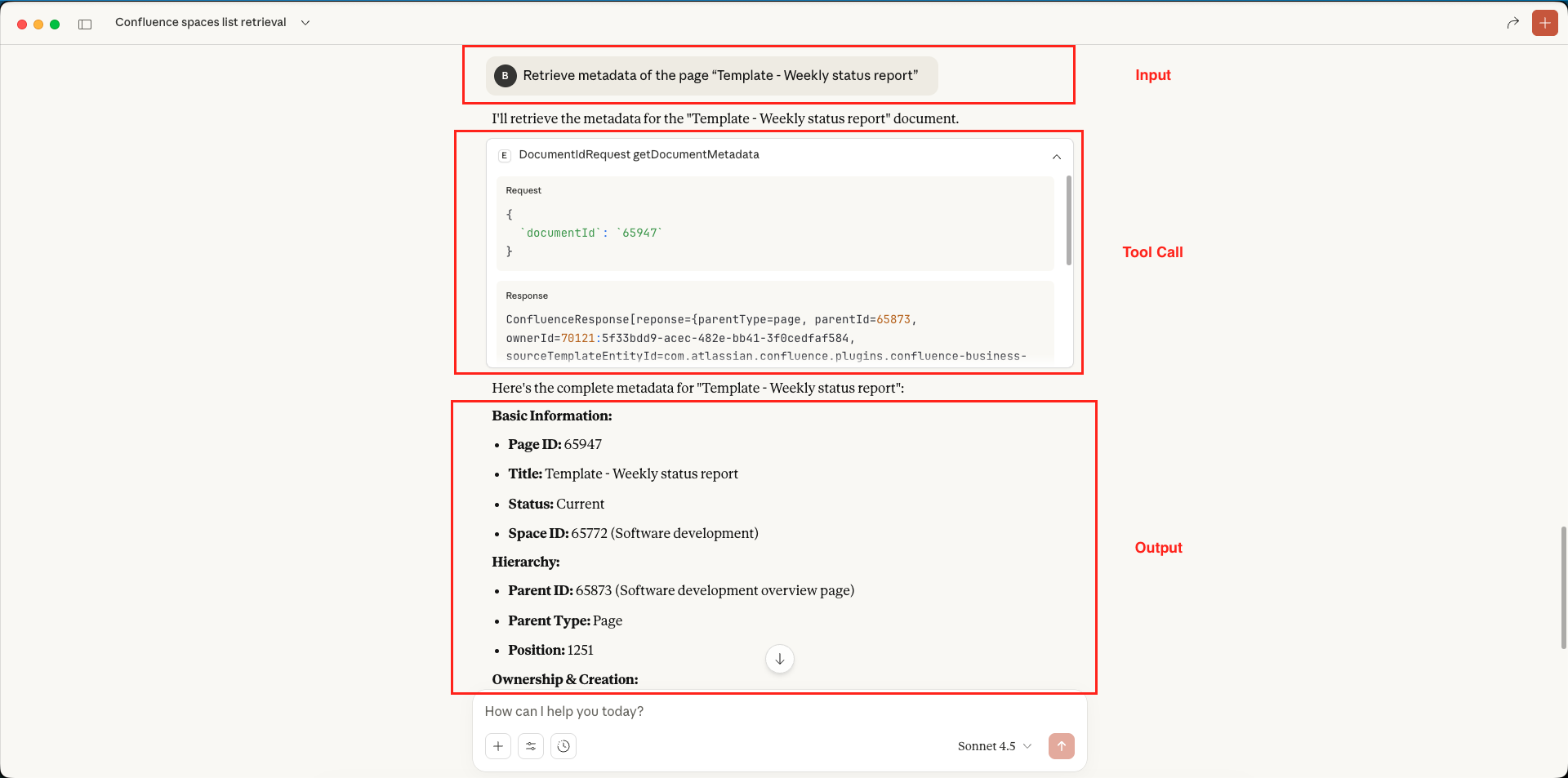 Confluence MCP Server – Get Document Metadata – Claude Desktop
Confluence MCP Server – Get Document Metadata – Claude Desktop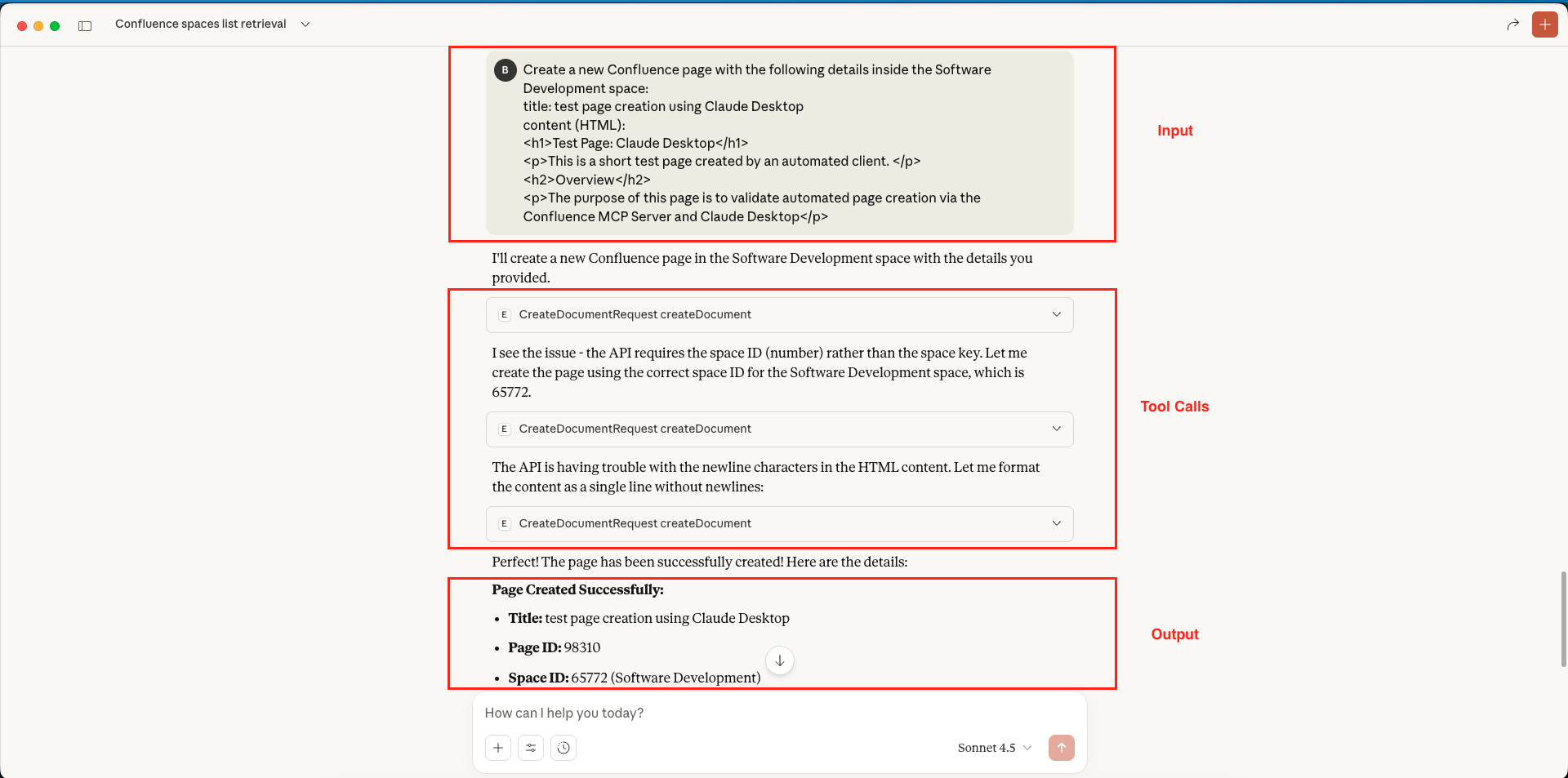 Confluence MCP Server – Create New Document – Claude Desktop
Confluence MCP Server – Create New Document – Claude Desktop New Confluence Page Created – Claude Desktop
New Confluence Page Created – Claude Desktop6. Video Tutorial
For a complete walkthrough, check out our video tutorial. We build the Confluence MCP Server from the ground up, providing a live demonstration of how to verify your tools using the MCP Inspector and how to fully integrate them with Claude Desktop to enable real-time knowledge base management by AI.
📺 Watch on YouTube:
7. Source Code
The full source code for our Confluence MCP Server is available on our GitHub repository. The best way to learn is by doing, so we encourage you to clone the repo, set your OPENAI_API_KEY along with your Confluence credentials (CONFLUENCE_BASE_URL and CONFLUENCE_AUTH_TOKEN) as environment variables, and launch the Spring Boot application. This will let you connect the server to Claude Desktop or the MCP Inspector and start experimenting.
🔗 Embabel Confluence MCP Server: https://github.com/BootcampToProd/embabel-confluence-mcp-server
8. Things to Consider
As you build mcp server keep these best practices in mind:
- Rate Limits: REST APIs have limits. An AI might trigger many requests quickly, so consider adding rate limiting logic in production.
- Data Privacy: Remember the data flow: Confluence -> Your Java Server -> AI Client (e.g., Claude). When your server fetches a document, that content is sent to the AI model for processing. Be cautious when using public LLMs with highly sensitive or proprietary corporate data. Ensure your organization’s data policies allow for this, or use local LLMs where data never leaves your infrastructure.
- Scaling with CQL (Confluence Query Language): In our demo, we used listDocumentsInSpace. While this works for small spaces, imagine a space with 5,000 pages! Fetching all of them would be slow and might hit memory limits. For production, consider exposing a “Search” tool that uses CQL (Confluence Query Language). This allows the AI to find specific documents (e.g., title ~ “meeting” AND created > “2024-01-01”) without downloading the entire database.
- Audit Trails & Transparency: When an AI creates a page, Confluence will show it as created by the user associated with the API Token (likely you or a service account). To avoid confusion, it is a good practice to programmatically append a footer to the content, such as “<em>This page was auto-generated by the Embabel AI Agent.</em>”. This maintains transparency and lets teammates know why the formatting might look different.
- Human-in-the-Loop for Critical Actions: While listing spaces is harmless, updating or overwriting documentation is risky. The AI might misunderstand a prompt and overwrite a critical architectural decision record with a summary. For operations that modify existing content, consider implementing a “Human in the Loop” workflow where the AI generates a draft (creates a new page with [DRAFT] in the title) rather than directly modifying the live source of truth.
9. FAQs
Can I use this MCP server with Confluence Cloud and Confluence Server?
Yes! The code works with both Confluence Cloud and Confluence Data Center/Server. Just make sure to:
- Check the API documentation for your specific Confluence version
- Use the correct base URL for your installation
- Adjust API endpoints if using an older Confluence version
How do I add more Confluence operations?
Simply add new methods to ConfluenceService and expose them in ConfluenceMcpAgent
- Create the service method with the appropriate Confluence API call
- Add a corresponding method in the MCP agent with
@Actionand@AchievesGoal - Create a DTO if you need custom input parameters
- Restart the server, and the new tool will be available!
Can I use a different AI model instead of Grok?
Yes! You can configure any OpenAI-compatible model. Simply modify ConfigureOpenRouterModels.java to add your preferred model
10. Conclusion
In this article, we successfully built a Confluence MCP Server using the Embabel Framework. We demonstrated how to connect the “brain” of an AI agent to the “hands” of a standard REST API. This setup allows you to automate documentation tasks, fetch knowledge base articles, and manage content using simple natural language commands.
11. Learn More
Interested in learning more?
Embabel Framework: How to Build MCP Server
Add a Comment